ViT、DiT、MMDiT架构解析
ViT、DiT、MMDiT 这三种架构代表了 Transformer 模型在计算机视觉和多模态生成领域的演进脉络。从最初的图像分类,到取代 U-Net 成为扩散模型的骨干网络,再到处理复杂的图文多模态生成,Transformer 的潜力被不断挖掘。
一、ViT
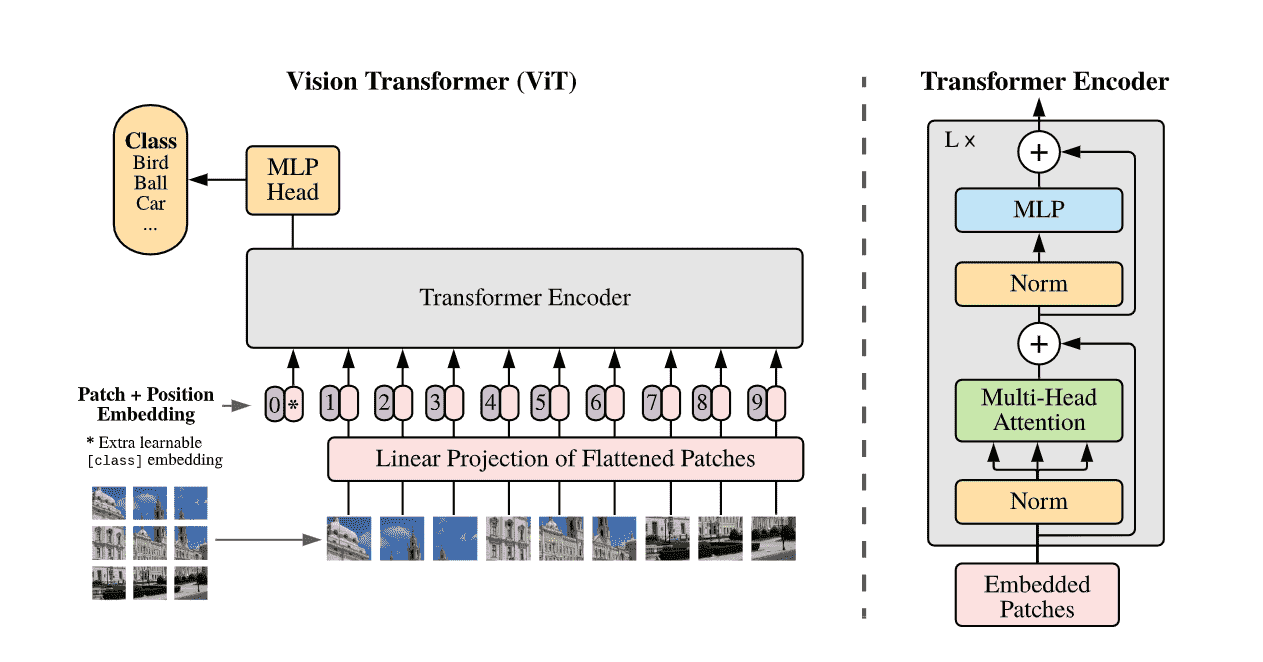
ViT (Vision Transformer) 论文:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,其核心思想非常直接:将图像视为一串文字(Tokens),从而直接套用在自然语言处理中大获成功的标准 Transformer 架构,彻底抛弃了传统的卷积神经网络(CNN)。
- 图像分块 (Patch Embedding):将一张完整的图像切分为固定大小的图像块(例如 像素的 Patch)。每个图像块被展平并映射为一个低维的线性向量(Token)。
- 位置编码 (Positional Encoding):因为 Transformer 本身没有空间位置概念(自注意力机制是置换不变的),ViT 为每个 Token 添加了可学习的位置编码,保留图像的二维空间信息。
- Class Token:借鉴了 BERT 的设计,在输入序列的开头加入一个额外的可学习 Token(
[CLS]),经过 Transformer 编码器后,该 Token 的输出特征直接用于最终的图像分类任务。
为了详细分析 ViT 的实现逻辑,我找到了 Hugging Face transformers 库的实现,下面的代码即 ViT 图像分类的代码,主要采用 vit-base-patch16-224 这一权重。接下来我将详细分析 ViT 的实现细节以及分类过程中数据尺度的变化。
1 | |
ViT 架构核心组件分析
基于 Hugging Face transformers 库的源码实现,ViT 分类模型 (ViTForImageClassification) 依赖三个主要组件:
- Image Processor (
ViTImageProcessor): 负责图像预处理,包括调整图像大小(如裁剪至 224x224)、标准化(归一化像素值),并将其转换为 PyTorch Tensor。 - Transformer Backbone (
ViTModel): 视觉 Transformer 的核心骨干网络,负责提取图像的全局特征表示。 - Classification Head: 一个附加在 Backbone 顶部的简单线性分类器(Linear Layer),专门用于将提取到的
[CLS]特征映射到具体的类别概率分布上。
深入 ViTModel 内部架构
该模型直接沿用了标准 Transformer 的 Encoder 结构,并在输入端针对图像数据做了特殊的适配:
- Patch Embeddings (
ViTPatchEmbeddings)
代码中并没有手动切片图像,而是巧妙地使用了一个二维卷积层nn.Conv2d,其kernel_size和stride均等于patch_size。这不仅一步完成了分块(Patchify),同时还实现了从像素空间到隐藏层维度(Hidden Size)的线性投影。 - Token 拼接与位置编码 (
ViTEmbeddings)
分块后的序列会首先与一个可学习的[CLS]Token(代码中的self.cls_token)在序列维度进行拼接。紧接着,整个序列加上可学习的一维位置编码(self.position_embeddings),最后通过 Dropout 层。 - Transformer Encoder (
ViTEncoder&ViTLayer)
包含多层标准的 Transformer 块。每一层(ViTLayer)都包含自注意力机制(ViTAttention)和前馈神经网络(ViTIntermediate+ViTOutput)。在此过程中,特征始终使用LayerNorm进行归一化,且序列长度保持不变。 - 分类输出提取 (
ViTForImageClassification)
在经过多层 Transformer 处理后,模型并不使用所有的图像块输出,而是专门提取序列的第一个 Token(即sequence_output[:, 0, :],对应[CLS]Token)作为整张图像的全局特征表示,送入线性分类头预测类别。
数据输入到输出的尺度变化
为了直观展现特征维度的演变,我们以 vit-base-patch16-224 的标准配置为例:
- Batch Size (N): 1
- 输入图像尺寸 (H × W): 224 × 224
- 输入通道数 ©: 3 (RGB)
- Patch Size (p): 16
- 隐藏层维度 (D): 768
- 分类标签数 (Num Labels): 1000 (ImageNet 类别)
以下是数据在前向传播中的完整尺度变化追踪:
1. 图像预处理 (Processor 级别)
- 操作: 缩放、裁剪并归一化原始图像。
- Shape: 转化为张量送入模型 ➔ 1 × 3 × 224 × 224
2. Patchify 阶段 (ViTPatchEmbeddings)
- 操作:
embeddings = self.projection(pixel_values).flatten(2).transpose(1, 2) - 计算: 使用 16×16 卷积核且步长为 16 的
Conv2d。输出的网格尺寸为 (224/16) × (224/16) = 14 × 14。总 Patch 数量 T = 196。卷积后通道数变为 D (768)。随后将高宽维度展平。 - Shape: N × C × H × W ➔ N × D × 14 × 14 ➔ 1 × 196 × 768
3. 嵌入与拼接阶段 (ViTEmbeddings)
- 操作: 拼接
[CLS]Token,并加上位置编码。 - 计算:
cls_token的形状为 1 × 1 × 768。拼接到 196 个 Patch 前,序列总长度变为 197。位置编码position_embeddings形状为 1 × 197 × 768。 - Shape: 1 × 197 × 768
4. Transformer Encoder 阶段 (ViTEncoder)
- 操作: 数据依次通过 12 层 Transformer Block。
- 计算: 在自注意力(多头注意力头数通常为 12)和 MLP 块中,序列长度(197)和特征维度(768)均不发生改变。
- Shape: 保持 1 × 197 × 768
5. 特征提取与分类输出 (ViTForImageClassification)
- 操作 1 (提取
[CLS]Token):pooled_output = sequence_output[:, 0, :]
从序列中切片出索引为 0 的 Token 向量,摒弃其他 196 个图像块特征。 - Shape: 1 × 197 × 768 ➔ 1 × 768
- 操作 2 (分类头映射):
logits = self.classifier(pooled_output)
通过一个全连接层(从 768 维映射到 1000 维),生成对应 ImageNet 分类的 Logits 分数。 - Shape: 1 × 1000
二、DiT
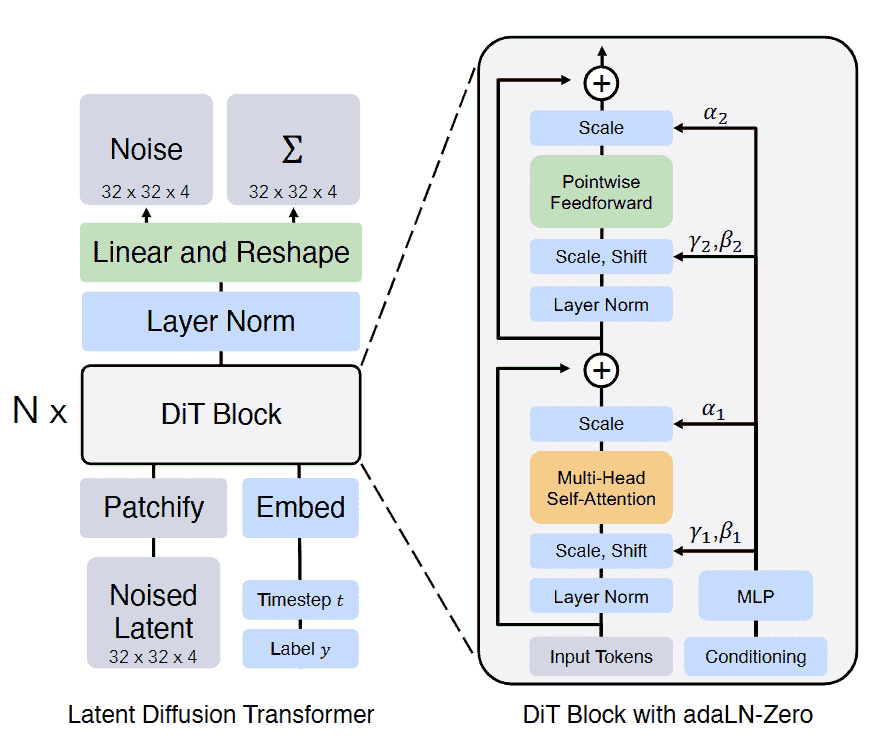
DiT (Diffusion Transformer) 论文:Scalable Diffusion Models with Transformers。在扩散模型(Diffusion Models)领域,U-Net 一直是标准的去噪骨干网络。DiT 则用 Transformer 替换了 U-Net,证明了 Transformer 在图像生成中同样具备强大的统治力。
- 潜空间操作 (Latent Space):DiT 继承了 Latent Diffusion 的思想,不直接在像素空间操作,而是将图像压缩到低维潜空间中。它将潜空间特征图切分为 Patches,作为 Transformer 的输入序列。
- 条件注入 (Conditioning):扩散模型需要知道当前的去噪步数(Timestep)和生成条件(如类别标签)。DiT 放弃了传统的交叉注意力注入,创新性地使用了 adaLN-Zero (Adaptive Layer Norm)。它通过多层感知机(MLP)将时间步和条件特征映射为缩放(Scale)和偏移(Shift)参数,直接作用于 Transformer 块的层归一化中。
为了详细分析 DiT 的实现逻辑,我找到了 Hugging Face diffusers 库的实现,下面的代码即 DiT 生成图像的代码,主要采用 DiT-XL-2-256 这一权重。接下来我将详细分析 DiT 的实现细节以及生成过程中数据尺度的变化。
1 | |
DiT 架构核心组件分析
基于 Hugging Face diffusers 库的实现,DiT 的生成管线 (DiTPipeline) 依赖三个主要组件:
- VAE: 负责在像素空间和隐空间之间进行转换。扩散和去噪过程都在降维后的隐空间中进行,大幅降低计算成本。
- Scheduler: 控制扩散过程的噪声添加和去噪步数。
- Transformer Backbone (
DiTTransformer2DModel): DiT 的核心引擎,负责在给定当前步数和类别条件的情况下,预测并消除隐向量中的噪声。
深入 DiTTransformer2DModel 内部架构
该模型主要由三个阶段构成,借鉴了 Vision Transformer (ViT) 的处理逻辑,并在输出阶段做了针对生成任务的设计:
- Patchify (图像分块与嵌入)
通过pos_embed将二维的隐特征图切分为非重叠的 Patch,并展平为一维序列。这使得图像数据可以像文本 Token 一样被 Transformer 处理。 - Transformer Blocks (核心计算)
包含多层BasicTransformerBlock。这里采用了自适应层归一化(AdaLN-Zero)。时间步和类别条件并未作为额外的 Token 拼接,而是被映射为缩放(Scale)和平移(Shift)参数,直接作用于每一个 Block 的 Normalization 层。 - Pre-Output (输出前调制,包含
proj_out_1)
在最终输出前,模型需要将特征还原。proj_out_1在此阶段扮演关键角色:它是一个线性层,专门接收全局条件嵌入(时间步+类别),并将其投影生成最终 LayerNorm 所需的自适应缩放和平移参数。 - Unpatchify (反分块与输出)
通过线性层proj_out_2和重塑操作,将一维序列还原回二维的图像隐特征形状,输出预测的噪声。
数据输入到输出的尺度变化
为了更直观地理解,我们假设以下标准配置,并开启 Classifier-Free Guidance (CFG):
- 实际 Batch Size (N): 2 (1 个无条件输入 + 1 个条件输入)
- 隐通道数 ©: 4 (对应 VAE 输出)
- 隐图像尺寸 (H W): 32 32 (相当于 256 256 像素图像的 8 倍降采样)
- Patch Size (p): 2
- 注意力头数 (Heads): 16
- 单头维度 (Head_dim): 72
- 隐藏层维度 (D): 16 72 = 1152
- 输出通道数 (C_out): 8 (包含预测噪声 4 通道 + 预测方差 4 通道)
以下是数据在推理前向传播中的完整尺度变化追踪:
1. 初始输入准备 (Pipeline 级别拼接)
- 图像隐向量 (Latents): 初始生成 的高斯噪声。为了同时进行无条件(Unconditional)和有条件(Conditional)的前向传播,隐向量在 Batch 维度被复制拼接(Concatenate)。
- Shape:
- 时间步 (): 当前去噪步数(如 999),同样在 Batch 维度翻倍。
- Shape: (一维张量,内容如
[999, 999])
- Shape: (一维张量,内容如
- 类别标签 (
class_labels): 包含一个“空标签”(通常用特殊的 ID 表示,或用可学习的 null 向量)和一个“真实标签”(如白鲨的 ID)。- Shape: (一维张量,内容如
[null_id, 2])
- Shape: (一维张量,内容如
2. Patchify 阶段 (图像进入 Transformer)
- 操作:
hidden_states = self.pos_embed(hidden_states) - 计算: 的图像隐特征图被切分为 的 Patch。单张图 Patch 数量 。每个 Patch 被线性投影到隐藏层维度 (1152)。
- Shape: 从二维张量变为一维序列:
3. 条件映射阶段 (全局信息融合)
- 操作: 时间步 和
class_labels分别通过各自的 Embedding 层和 MLP 投影到维度 ,然后相加融合。- 时间步 Embedding: 维度
- 类别标签 Embedding: 维度
- 融合条件 (Conditioning): 两者相加形成统一的全局特征向量。
- Shape:
4. Transformer Blocks 处理阶段 (AdaLN-Zero 注入)
- 操作: 序列 () 经过多层
BasicTransformerBlock。在每一个 Block 的AdaLayerNormZero层中注入全局条件。 - 计算与广播 (Broadcasting):
- 的全局条件特征通过一个线性层放大 6 倍,生成 6 个调制参数(用于 Self-Attention 和 MLP 的 Scale/Shift/Gate)。
- Shape 变化: 拆分为 6 份 的张量。
- 这些调制参数通过广播机制叠加到图像序列上。
- 输出 Shape: 经过所有 Attention 和 FFN 计算后,图像序列长度和特征维度严格保持不变:
5. Pre-Output 投影阶段 (proj_out_1 与 proj_out_2)
- 操作 1 (
proj_out_1最终调制): 原始的 融合条件再次输入proj_out_1,生成最终层归一化的 Scale 和 Shift 参数。 - 操作 2 (
proj_out_2降维): 调制后的特征输入proj_out_2,将维度 (1152) 映射回每个 Patch 的重建像素级维度:。 - Shape:
6. Unpatchify 阶段 (输出预测噪声)
- 操作: 序列重塑 (Reshape) 与重新排列维度。
- 计算: 将长度为 256 的序列还原为 的网格物理拼接。
- Shape:
7. CFG 计算与 VAE 解码 (Pipeline 级别)
- 操作 1 (CFG 融合): 从模型中获得预测输出后,在 Batch 维度将 切分为无条件预测 (
uncond) 和有条件预测 (cond),二者 Shape 皆为 。通过公式uncond + guidance_scale * (cond - uncond)得到最终的引导噪声预测。- 最终噪声 Shape:
- 操作 2 (Scheduler 降噪): 截取前 4 个通道 () 用于更新隐向量,进入下一步去噪循环。
- 操作 3 (VAE 解码): 所有推理步骤(如 25 步)结束后,最终的干净隐向量被送入 VAE 解码器,上采样 8 倍。
- 最终图像 Shape: (RGB 像素图像)
三、MMDiT
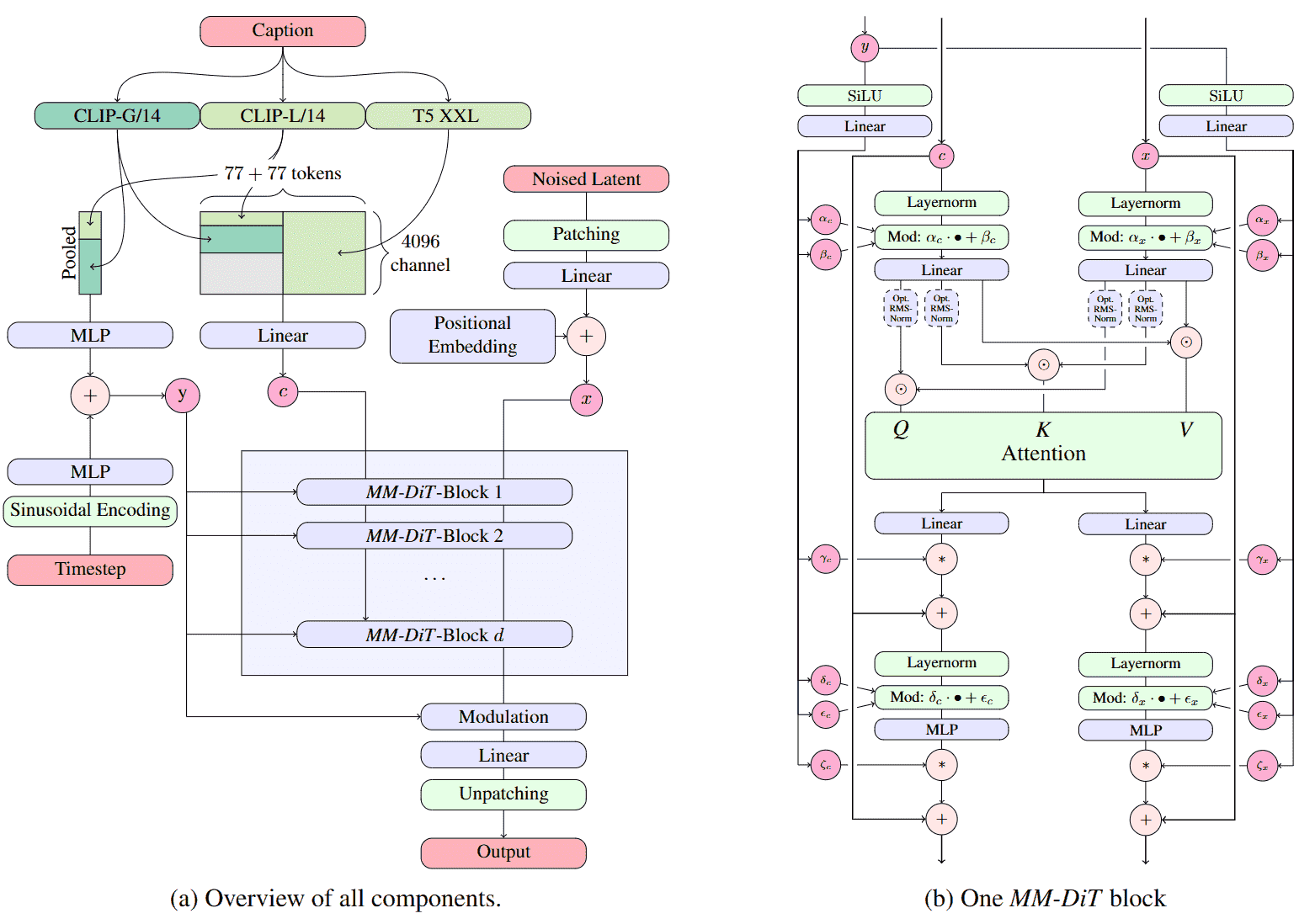
MMDiT(Multi-Modal Diffusion Transformer)论文:Scaling Rectified Flow Transformers for High-Resolution Image Synthesis,是提出 Stable Diffusion 3 的工作。MMDiT 在 DiT 的基础上进行了针对多模态(文本和图像)的架构升级,证明了 双流架构(Dual-Stream Architecture) 在复杂图文对齐上的统治力。
- 双流独立处理 (Dual-Stream):MMDiT 认为图像特征和文本特征属于截然不同的模态,传统的交叉注意力直接混合处理会相互干扰。因此,模型为图像 Tokens 和文本 Tokens 分别保留了独立的前馈神经网络(FFN)和层归一化(LayerNorm)。
- 联合注意力与条件注入 (Joint Attention & Conditioning):在注意力计算阶段,MMDiT 将图像和文本的 Tokens 拼接在一起,在一个统一的自注意力机制中进行深度交互。同时,去噪步数(Timestep)和全局文本特征被融合,通过 adaLN-Zero 映射为缩放(Scale)和偏移(Shift)参数,独立作用于图像和文本流的归一化层。
为了详细分析 MMDiT 的实现逻辑,我找到了 Hugging Face diffusers 库的实现,下面的代码即 MMDiT(Stable Diffusion 3 Medium)生成图像的代码。接下来我将详细分析 MMDiT 的实现细节以及生成过程中数据尺度的变化。
1 | |
MMDiT 架构核心组件分析
基于 Hugging Face diffusers 库的实现,MMDiT 的生成管线 (StableDiffusion3Pipeline) 依赖四个主要组件:
- Text Encoders: 多文本编码器集群。SD3 史无前例地使用了三个模型:两个 CLIP(
clip-vit-large-patch14和CLIP-ViT-bigG)提供全局与序列语义,以及一个 T5(t5-v1_1-xxl)提供深层细节理解。 - VAE (AutoencoderKL): 负责在像素空间和隐空间之间转换。SD3 使用了更高压缩维度的 VAE,潜空间通道数增加到了 16,以保留更多细节。
- Scheduler (
FlowMatchEulerDiscreteScheduler): 控制去噪过程。SD3 采用了前沿的流匹配(Flow Matching)调度策略来替代传统的 DDPM。 - Transformer Backbone (
SD3Transformer2DModel): 模型的核心骨干,负责在潜空间中去噪并对齐图文多模态特征。
深入 SD3Transformer2DModel 内部架构
该模型结构将 DiT 的思想扩展到了双流结构,主要由以下几个阶段构成:
- Patchify & Embeddings (分块与嵌入)
通过pos_embed将 16 通道的二维隐特征图切分为 Patch,并展平为一维序列。同时,通过context_embedder映射文本的 Token 序列特征,通过time_text_embed融合当前的时间步和文本的全局池化特征。 - Joint Transformer Blocks (核心计算)
包含多层JointTransformerBlock。这是 MMDiT 的精髓: 时间步和全局文本特征被映射为参数,分别对图像流和文本流进行独立调制(AdaLN-Zero)。随后,两路 Tokens 送入同一个Attention层共享 Q、K、V 投影矩阵实现跨模态融合。计算结束后被再次拆分,进入各自的独立 FFN 进行非线性变换。 - Pre-Output & Unpatchify (输出前调制与反分块)
经过所有 Block 处理后,模型丢弃文本流。图像特征经过最后的自适应归一化 (norm_out) 和线性映射 (proj_out) 降维,最后通过重塑(Reshape)与 Einsum 操作从一维序列还原回二维的隐特征形状。
数据输入到输出的尺度变化
为了更直观地理解,我们以生成 1024 × 1024 图像、开启无分类器引导(CFG)的标准配置为例:
- Batch Size (N): 2 (正向提示词 + 负向提示词)
- 隐通道数 ©: 16 (SD3 VAE 特性)
- 隐图像尺寸 (H × W): 128 × 128 (1024 的 8 倍降采样)
- Patch Size (p): 2
- 隐藏层维度 (D): 1536
- 文本序列长度 (L_txt): 333
以下是数据在推理前向传播中的完整尺度变化追踪:
1. 文本编码与融合 (Pipeline 级别)
- 操作: 提取并拼接文本特征。
- 计算:
- CLIP-L (77 × 768) 与 CLIP-G (77 × 1280) 在特征维度拼接为 2048 维,并补零至 4096 维。
- 将上述结果与 T5 (256 × 4096) 在序列维度拼接:77 + 256 = 333。
- 提取双 CLIP 的全局池化特征并拼接为 2048 维。
- Shape: 序列特征 ➔ 2 × 333 × 4096;全局池化特征 ➔ 2 × 2048
2. 初始隐向量与时间步准备 (Pipeline 级别)
- 操作: 生成随机高斯噪声,获取当前步数。
- Shape: 隐特征图 ➔ 2 × 16 × 128 × 128;时间步标量 ➔ 2
3. Patchify 与特征映射阶段 (进入 Transformer)
- 操作 1 (Image Patchify): 隐特征图被切分为 2 × 2 的 Patch。总数量 。
Shape: 图像序列hidden_states➔ 2 × 4096 × 1536 - 操作 2 (Text Mapping): 文本序列通过
context_embedder降维。
Shape: 文本序列encoder_hidden_states➔ 2 × 333 × 1536 - 操作 3 (Time-Text Fusion): 时间标量升维后与映射后的全局文本池化特征相加。
Shape: 全局条件temb➔ 2 × 1536
4. 深入 JointTransformerBlock 数据流:条件注入与双流交互
当数据进入 JointTransformerBlock 时,模型必须同时处理三种数据:图像流、文本流,以及包含时间/全局语义的全局条件 temb。整个模块的内部交互顺滑地融合了以下几个关键处理阶段:
- 独立条件注入 (Dual AdaLN-Zero):
temb(2 × 1536) 作为统帅,分别向图像流和文本流下达“调制指令”。对于图像流 (self.norm1),temb通过线性层映射放大 6 倍并切分为 6 份,产生如shift_msa、scale_msa、gate_msa、shift_mlp、scale_mlp、gate_mlp6 个形状皆为 2 × 1536 的张量,图像序列hidden_states在进行下面的Joint Attention前,先经过LayerNorm,然后再通过shift_msa和scale_msa进行调制。同理,对于文本流 (self.norm1_context),temb经过独立的线性层映射生成 6 个专属的同形状控制参数,在进行下面的Joint Attention前,也是用前两个参数进行调制。 - 跨模态联合注意力 (Joint Attention): 被独立归一化后的图像和文本序列被共同送入
self.attn。在底层算子中,图像序列(长度 4096)和文本序列(长度 333)会在序列维度上拼接 (Concat),形成长度为 4429 的超级序列进行 Self-Attention 计算。这种设计使得图像 Patch 可以“看到”所有文本 Token,文本 Token 也能“看到”所有图像 Patch,实现深度的特征对齐。计算完成后,超级序列被重新拆分为图像的attn_output(2 × 4096 × 1536) 和文本的context_attn_output(2 × 333 × 1536)。 - 独立门控与残差 (Gating & Residuals): 拆分后的数据回归各自的独立处理轨道。图像侧执行门控
gate_msa进行调制attn_output = gate_msa * attn_output,随后进行残差连接hidden_states = hidden_states + attn_output。文本侧同样执行 类似操作。 - 独立前馈网络 (Dual FFN): 图像流和文本流各自进入专属的
self.norm2和 FFN 网络,图像流在进入 FFN 网络前,先经过LayerNorm,然后再通过shift_mlp和scale_mlp进行调制,离开 FFN 网络后,使用门控gate_mlp进行调制。文本侧同样执行 类似操作。两股数据流的输出 Shape 严格保持不变:图像流维持在 2 × 4096 × 1536,文本流维持在 2 × 333 × 1536。
5. 输出投影与 Unpatchify 阶段 (输出重建)
- 操作 1 (丢弃与投影): 文本流在最后阶段被完全丢弃。图像特征经过
self.norm_out调制后,输入self.proj_out层,从维度 D (1536) 映射回重建目标维度,即 。
Shape: ➔ 2 × 4096 × 64 - 操作 2 (反分块): 将长度为 4096 的序列还原为 64 × 64 的网格,展开为二维特征图。
Shape: 2 × 16 × 128 × 128
6. VAE 解码 (Pipeline 级别)
- 操作: 调度器去噪循环结束后,取出条件预测的隐变量送入 VAE 解码器 (
vae.decode)。 - Shape: 1 × 16 × 128 × 128 ➔ 1 × 3 × 1024 × 1024 (最终 RGB 像素图像)
四、演进关系与对比总结
| 特性 | ViT (Vision Transformer) | DiT (Diffusion Transformer) | MMDiT (Multi-Modal Diffusion Transformer) |
|---|---|---|---|
| 主要任务 | 判别任务(图像分类、特征提取) | 生成任务(条件/无条件图像生成) | 多模态生成任务(高质量文本到图像生成) |
| 输入模态 | 单模态(图像 Patches) | 单模态(潜空间图像 Patches + 条件标签) | 双模态(潜空间图像 Patches + 文本序列) |
| 架构重点 | 证明 Transformer 可用于视觉 | 取代 U-Net,引入 adaLN 注入扩散条件 | 引入双流网络与联合注意力,解决图文对齐 |
| 条件注入方式 | 无(或简单的 Class Token) | adaLN-Zero | adaLN 配合多模态联合自注意力 |
| 历史意义 | 视觉 Transformer 的奠基者 | 开启了基于 Transformer 的生成大模型时代 | 树立了当前 AI 绘画与多模态生成的新标杆 |
总的来说,ViT 提供了将视觉转化为序列的基础,DiT 证明了这种序列化架构可以用于主导复杂的去噪生成过程,而 MMDiT 则是将多模态数据在这个序列化生成框架内实现了最深度的融合。