Stable Diffusion 1.5 架构分析
Stable Diffusion 1.5 架构分析
目录
- 概述
- 经典 UNet 结构回顾
- Stable Diffusion UNet 整体架构
- CrossAttnDownBlock2D
- Transformer2DModel
- Attention
- 张量维度流转总结
概述
Stable Diffusion 1.5(SD 1.5)是基于潜在扩散模型(Latent Diffusion Model, LDM)构建的文生图系统。其核心降噪网络为经过大幅改造的 UNet,在经典编解码器结构之上引入了时间步嵌入(time embedding)和文本交叉注意力(cross-attention),使模型能够在文本条件指导下对潜空间噪声图进行逐步去噪[5][8]。
SD 1.5 UNet 的输入输出均在 潜空间(latent space) 中进行,空间分辨率为原图的 1/8。以生成 512×512 图像为例,UNet 处理的 latent 尺寸为 64×64,通道数为 4[4]。
经典 UNet 结构回顾
原始 UNet 由 Ronneberger 等人于 2015 年提出,最初用于医学图像分割任务,其最大特点是编码器-解码器结构配合跳跃连接(skip connection)[1][3][6]。
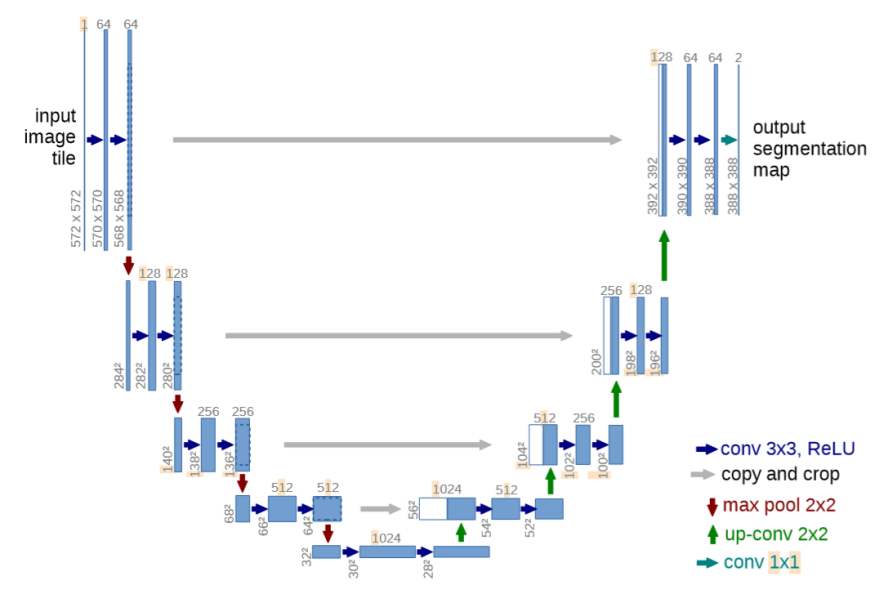
图 1:经典 UNet 结构。左侧为编码器(下采样路径),右侧为解码器(上采样路径),灰色箭头表示跳跃连接(copy and crop)。
主要组成:
| 组件 | 说明 |
|---|---|
| 编码器 | 由多组卷积 + 最大池化构成,逐层降低空间分辨率、增加通道数 |
| 解码器 | 由上采样卷积逐层恢复分辨率 |
| 跳跃连接 | 将编码器各层特征图拼接(concat)到解码器对应层,保留浅层细节信息 |
| 瓶颈层 | 网络最深处,捕获全局语义信息 |
SD 1.5 继承了这一对称结构,并在此基础上引入时间步嵌入和跨模态注意力机制,以支持扩散过程中的条件去噪[4][5][9]。
Stable Diffusion UNet 整体架构
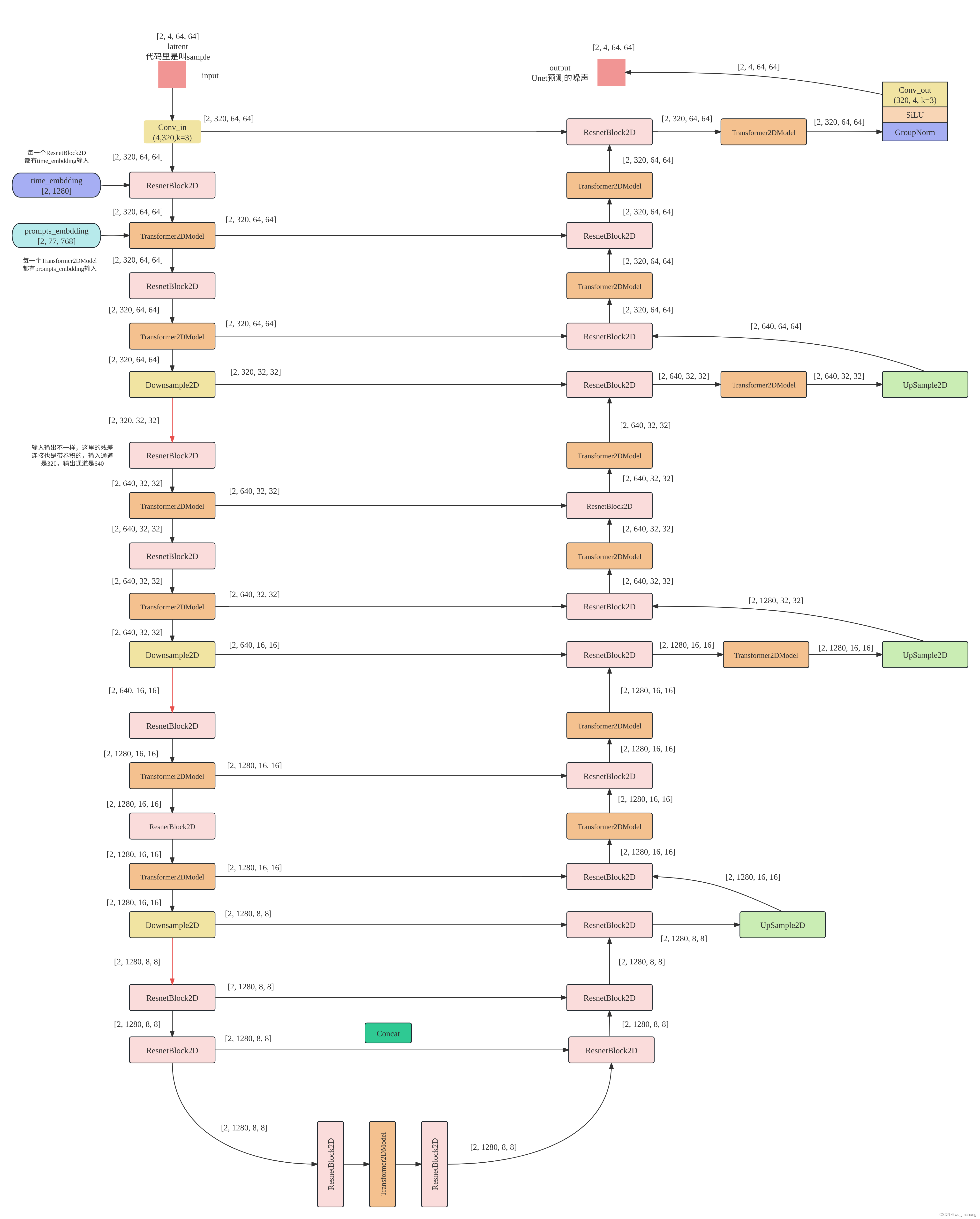
图 2:SD 1.5 UNet 完整数据流图。粉色块为 ResnetBlock2D,橙色块为 Transformer2DModel,绿色块为 UpSample2D/DownSample2D,跳跃连接以带箭头的横向连线表示。
输入
| 输入 | 形状 | 说明 |
|---|---|---|
latent |
[2, 4, 64, 64] |
加噪后的潜变量,batch=2(CFG 需要条件/无条件各一份) |
time_embedding |
[2, 1280] |
当前时间步 的正弦位置编码,经 MLP 映射到 1280 维 |
prompts_embedding |
[2, 77, 768] |
文本编码器(CLIP)输出的 token 序列,77 个 token,每个 768 维 |
总体结构
网络分为三个部分:
- Encoder(下采样路径):4 个下采样阶段,空间分辨率从 64×64 逐步降至 8×8,通道数从 320 增至 1280。
- Middle Block(瓶颈层):在 8×8 分辨率下进行深度特征融合,结构为
ResnetBlock2D → Transformer2DModel → ResnetBlock2D。 - Decoder(上采样路径):4 个上采样阶段,逐步恢复分辨率,每层通过 concat 融合编码器对应层的跳跃连接特征。
各阶段通道与分辨率
| 阶段 | 分辨率 | 通道数 | 模块类型 |
|---|---|---|---|
初始卷积 Conv_in |
64×64 | 320 | Conv2d(4, 320, k=3) |
| DownBlock 1 | 64×64 | 320 | CrossAttnDownBlock2D × 2 |
| DownBlock 2 | 32×32 | 640 | CrossAttnDownBlock2D × 2 |
| DownBlock 3 | 16×16 | 1280 | CrossAttnDownBlock2D × 2 |
| DownBlock 4 | 8×8 | 1280 | DownBlock2D(无注意力)× 2 |
| Middle | 8×8 | 1280 | ResnetBlock2D + Transformer2DModel + ResnetBlock2D |
| UpBlock 1 | 8×8 → 16×16 | 1280 | CrossAttnUpBlock2D × 3 |
| UpBlock 2 | 16×16 → 32×32 | 1280 → 640 | CrossAttnUpBlock2D × 3 |
| UpBlock 3 | 32×32 → 64×64 | 640 → 320 | CrossAttnUpBlock2D × 3 |
| UpBlock 4 | 64×64 | 320 | UpBlock2D(无注意力)× 3 |
输出卷积 Conv_out |
64×64 | 4 | GroupNorm → SiLU → Conv2d(320, 4, k=3) |
注:解码器每个 UpBlock 包含 3 个重复单元(而非 2 个),是因为需要额外融合来自编码器瓶颈层的跳跃连接。编码器中每层
Downsample2D之前的输出也会通过跳跃连接传递给解码器。
CrossAttnDownBlock2D
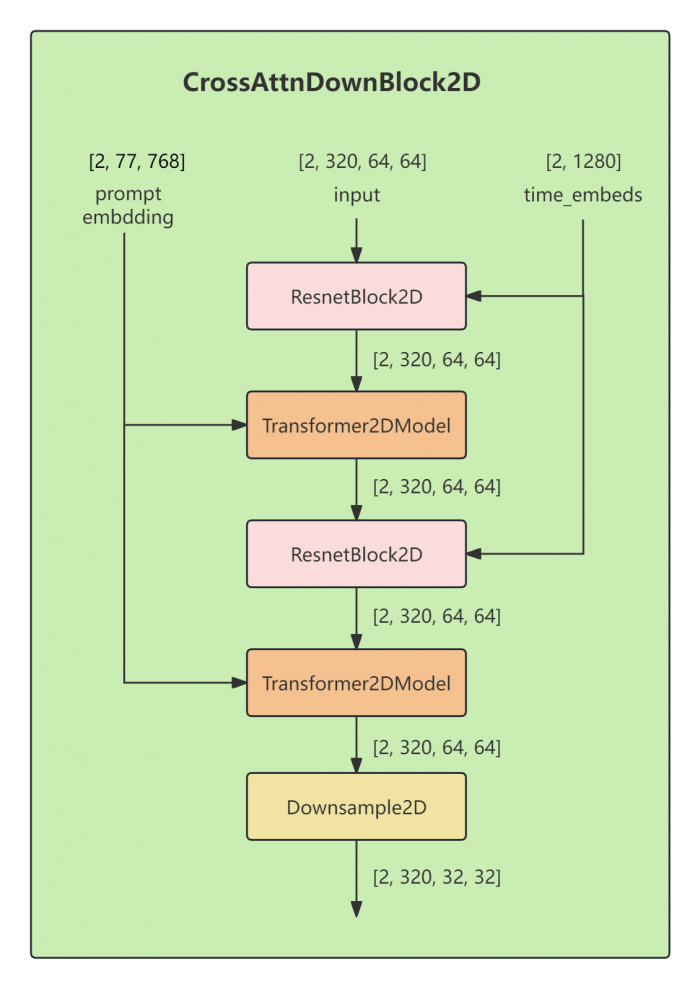
图 3:CrossAttnDownBlock2D 内部结构(以第一个下采样阶段为例,输入形状 [2, 320, 64, 64])。
CrossAttnDownBlock2D 是 SD UNet 编码器的核心组成单元,每个模块包含:
- ResnetBlock2D:融合时间步嵌入,完成残差特征变换
- Transformer2DModel:引入文本交叉注意力,实现图文对齐
- 以上两步重复 2 次
- Downsample2D:步长为 2 的卷积,将空间分辨率减半
数据流(以第一阶段为例):
1 | |
每个 ResnetBlock2D 接收 time_embeds 并通过加法融合;每个 Transformer2DModel 接收 prompt_embedding 并通过交叉注意力融合。二者交替叠加,确保空间特征在每个尺度上都同时融合了时序信息和语义信息[2][4]。
解码器对应的 CrossAttnUpBlock2D 结构与之对称,额外在 ResnetBlock2D 输入前拼接(concat)来自编码器的跳跃连接特征[9]。
Transformer2DModel
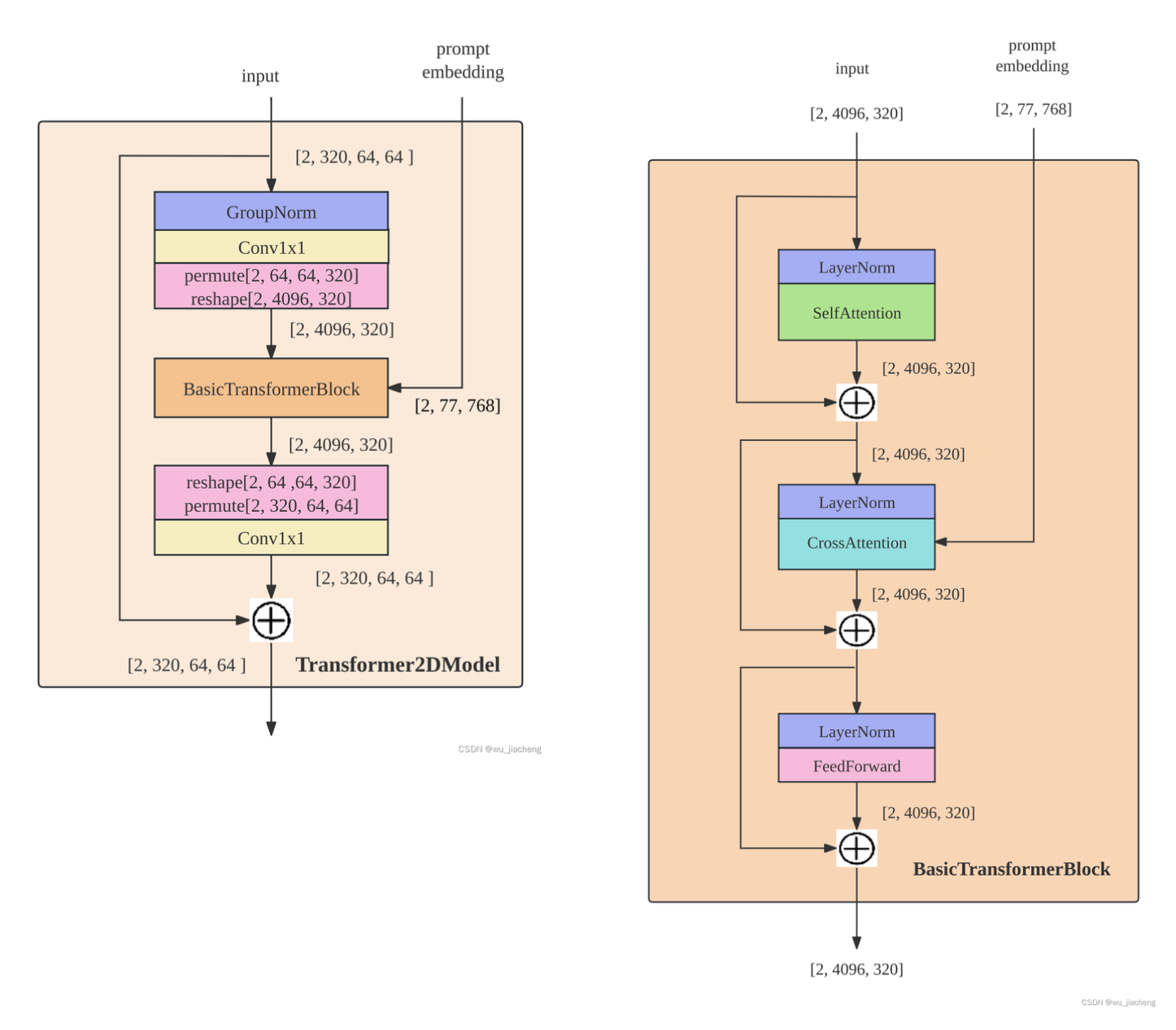
图 4:左侧为 Transformer2DModel 整体结构;右侧为内部 BasicTransformerBlock 结构。
Transformer2DModel
Transformer2DModel 负责在 2D 特征图上进行 Transformer 操作,其流程为:
1 | |
核心思路:将 2D 特征图的 H×W 维度展平为序列长度(64×64=4096),以 Transformer 处理后再 reshape 回 2D,最后与原输入相加形成残差连接[2][9]。
BasicTransformerBlock
每个 BasicTransformerBlock 包含 3 个子模块,均采用**前置归一化(Pre-Norm)**结构:
| 子模块 | 类型 | 说明 |
|---|---|---|
| 子层 1 | Self-Attention | Q、K、V 均来自特征本身,捕获空间位置间的依赖关系 |
| 子层 2 | Cross-Attention | Q 来自特征,K/V 来自文本 prompt embedding,实现图文对齐 |
| 子层 3 | Feed-Forward | 两层全连接(带 GEGLU 激活),逐位置变换 |
每个子层后均有残差加法(⊕),形成标准的 Pre-LN Transformer 结构。
Attention
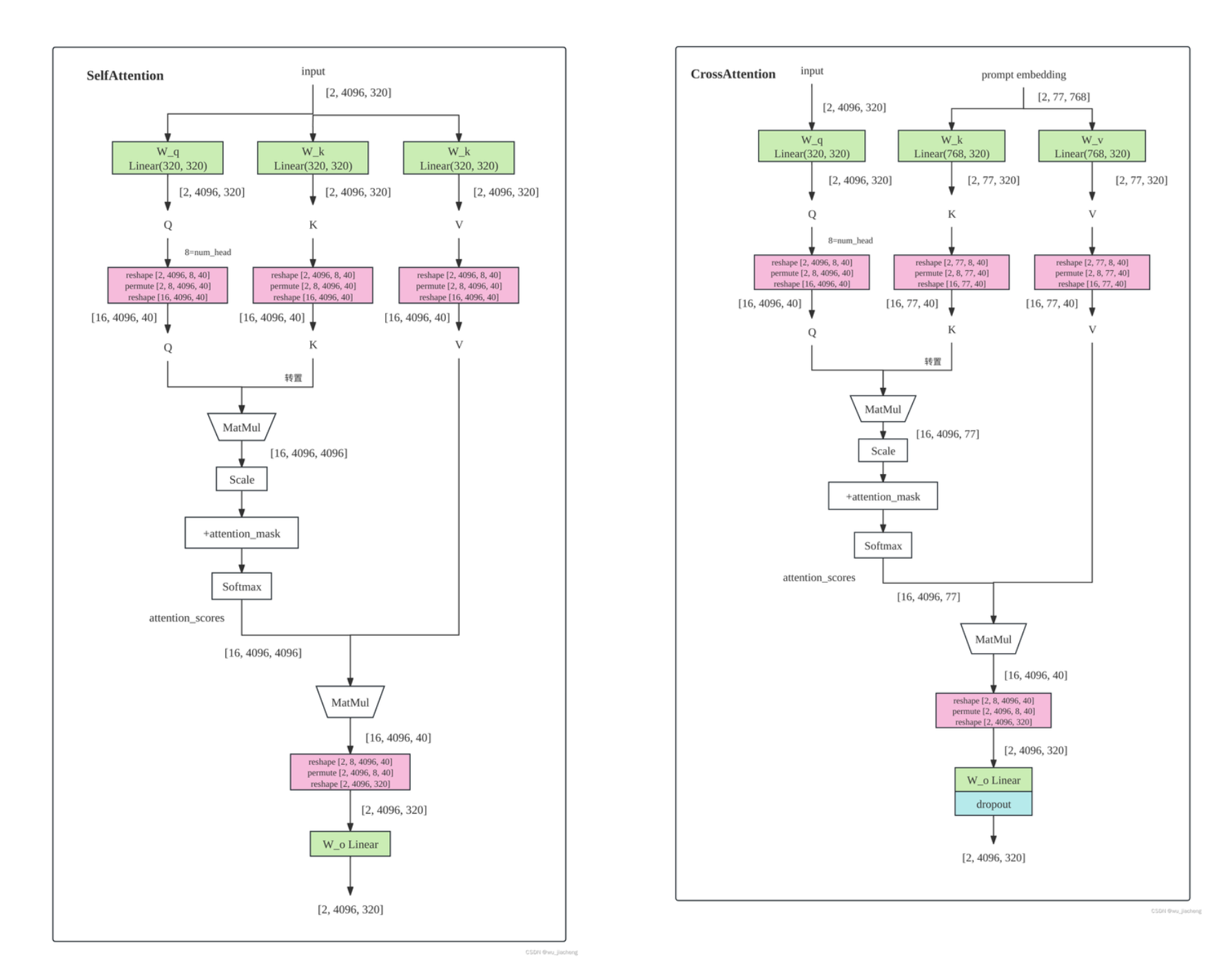
图 5:左侧为 SelfAttention;右侧为 CrossAttention。两者均采用多头注意力机制(num_heads=8)。
Self-Attention
输入特征形状:[2, 4096, 320],注意力头数:8,每头维度:40
1 | |
Cross-Attention
Cross-Attention 与 Self-Attention 的关键区别在于 K、V 来自文本 prompt embedding:
1 | |
Cross-Attention 的注意力矩阵形状为 [16, 4096, 77],每个图像位置(共 4096 个)对 77 个文本 token 计算相似度,从而将文本语义"写入"图像特征的每个空间位置[2][5][8]。
张量维度流转总结
| 位置 | 张量形状 | 说明 |
|---|---|---|
| UNet 输入 | [2, 4, 64, 64] |
加噪 latent |
| Conv_in 后 | [2, 320, 64, 64] |
初始特征图 |
| DownBlock 1 后 | [2, 320, 32, 32] |
第一次下采样 |
| DownBlock 2 后 | [2, 640, 16, 16] |
第二次下采样 |
| DownBlock 3 后 | [2, 1280, 8, 8] |
第三次下采样 |
| DownBlock 4 后 | [2, 1280, 8, 8] |
无注意力纯卷积 |
| Middle 后 | [2, 1280, 8, 8] |
瓶颈层特征 |
| UpBlock 1 后 | [2, 1280, 16, 16] |
第一次上采样 |
| UpBlock 2 后 | [2, 640, 32, 32] |
第二次上采样 |
| UpBlock 3 后 | [2, 320, 64, 64] |
第三次上采样 |
| UpBlock 4 后 | [2, 320, 64, 64] |
无注意力纯卷积 |
| Conv_out 后 | [2, 4, 64, 64] |
预测噪声 |
Transformer 内部展平后序列长度对应关系:
| 特征图尺寸 | 序列长度(H×W) |
|---|---|
| 64×64 | 4096 |
| 32×32 | 1024 |
| 16×16 | 256 |
| 8×8 | 64 |
参考文献
- Ronneberger O, Fischer P, Brox T. U-Net: Convolutional Networks for Biomedical Image Segmentation[J]. arXiv preprint, 2015. https://arxiv.org/abs/1505.04597 ↩
- 周弈帆. Stable Diffusion 3 原版实现及 Diffusers 实现源码解读[EB/OL]. 2024-01-23. https://zhouyifan.net/2024/01/23/20230713-SD3/ ↩
- Bimant. U-Net 简明教程[EB/OL]. http://www.bimant.com/blog/unet-crash-tutorial/ ↩
- xd_wjc. Stable Diffusion 1.5 网络结构——超详细原创[EB/OL]. CSDN, 2023. https://blog.csdn.net/xd_wjc/article/details/134441396 ↩
- 知乎专栏. Stable-Diffusion 模型结构详解[EB/OL]. https://zhuanlan.zhihu.com/p/638867353 ↩
- qq_58529413. UNet 网络详解[EB/OL]. CSDN, 2022. https://blog.csdn.net/qq_58529413/article/details/125704059 ↩
- xd_wjc. Stable Diffusion XL 网络结构[EB/OL]. CSDN, 2023. https://blog.csdn.net/xd_wjc/article/details/134530784 ↩
- HuggingFace CN Community. 从零开始学扩散模型[EB/OL]. https://huggingface.co/datasets/HuggingFace-CN-community/Diffusion-book-cn ↩
- bang. 理解 Stable Diffusion UNet 网络[EB/OL]. https://blog.cnbang.net/tech/3823/ ↩