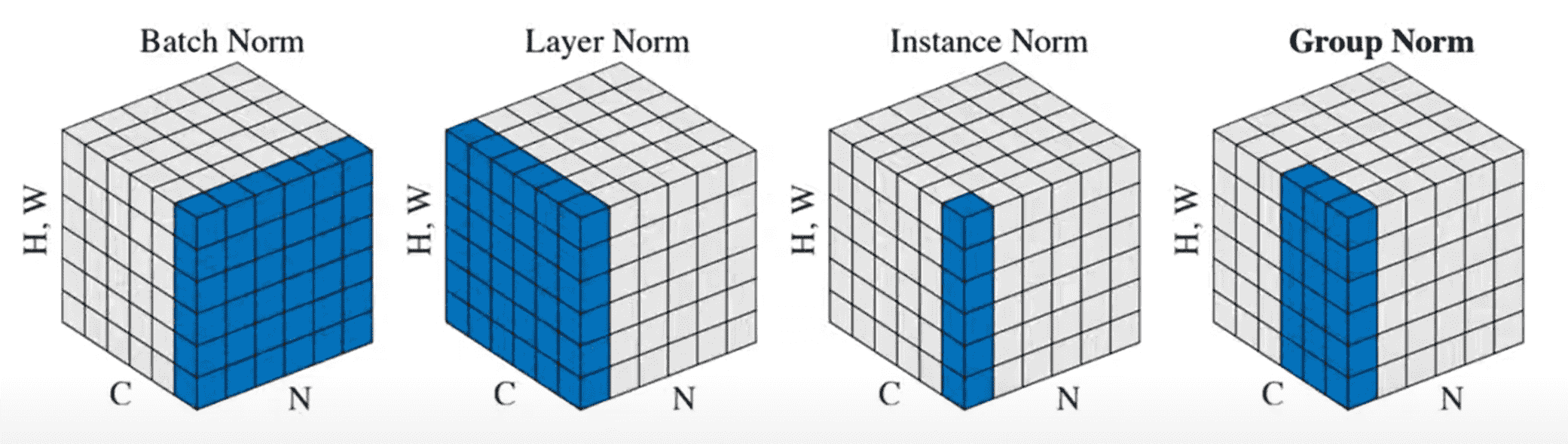
四种归一化方式介绍
上面的图非常直观地展示了深度学习中四种常见的归一化(Normalization)方法(RMSNorm 可视为 LayerNorm 的变体)。为了便于理解,我们假设输入的是一个图像特征张量(Tensor),其形状为 ( N , C , H , W ) (N, C, H, W) ( N , C , H , W )
N N N C C C H , W H, W H , W
图中的蓝色区域 代表了在进行一次 归一化操作时,计算均值(μ \mu μ σ 2 \sigma^2 σ 2
以下是四种归一化方法的详细理论、操作次数以及具体例子:
1. 批量归一化 (Batch Normalization, BatchNorm)
理论说明: 通道(Channel)维度 上保持独立,而跨越所有的样本(N N N H , W H, W H , W
归一化操作次数: C C C
具体例子: ( 4 , 64 , 32 , 32 ) (4, 64, 32, 32) ( 4 , 64 , 32 , 32 ) 32 × 32 32 \times 32 32 × 32
BatchNorm 会分别对这 64 个通道计算均值和方差。
操作次数:64 次。
每次计算涵盖的元素个数:4 × 32 × 32 = 4 \times 32 \times 32 = 4 × 32 × 32 =
2. 层归一化 (Layer Normalization, LayerNorm)
理论说明: 样本(Batch)维度 上保持独立,而跨越所有的通道(C C C H , W H, W H , W
归一化操作次数: N N N
具体例子: ( 4 , 64 , 32 , 32 ) (4, 64, 32, 32) ( 4 , 64 , 32 , 32 )
LayerNorm 会对这 4 张图片,每张图片单独计算一个均值和方差。
操作次数:4 次。
每次计算涵盖的元素个数:64 × 32 × 32 = 64 \times 32 \times 32 = 64 × 32 × 32 =
3. 实例归一化 (Instance Normalization, InstanceNorm)
理论说明: 样本(Batch)和通道(Channel)维度 上都保持独立,仅仅在空间维度(H , W H, W H , W
归一化操作次数: N × C N \times C N × C
具体例子: ( 4 , 64 , 32 , 32 ) (4, 64, 32, 32) ( 4 , 64 , 32 , 32 )
InstanceNorm 会对每一张图片的每一个通道单独计算均值和方差。
操作次数:4 × 64 = 4 \times 64 = 4 × 64 =
每次计算涵盖的元素个数:32 × 32 = 32 \times 32 = 32 × 32 =
4. 分组归一化 (Group Normalization, GroupNorm)
理论说明: C C C G G G 单个样本(Batch)内 ,跨越各个组内的通道和空间维度(H , W H, W H , W
归一化操作次数: N × G N \times G N × G
具体例子: ( 4 , 64 , 32 , 32 ) (4, 64, 32, 32) ( 4 , 64 , 32 , 32 ) G = 8 G = 8 G = 8
GroupNorm 会对 4 张图片,每张图片的 8 个分组分别计算均值和方差。
操作次数:4 × 8 = 4 \times 8 = 4 × 8 =
每次计算涵盖的元素个数:8 (组内通道数) × 32 × 32 = 8 \text{ (组内通道数)} \times 32 \times 32 = 8 ( 组内通道数 ) × 32 × 32 =
5. 均方根归一化 (Root Mean Square Normalization, RMSNorm)
理论说明:
归一化操作次数:
具体例子: ( N , S e q _ L e n , D ) (N, Seq\_Len, D) ( N , S e q _ L e n , D ) D D D
通用的归一化公式
前面四种归一化方法,底层执行的数学公式是完全相同的,唯一的区别在于参与计算的集合 S i S_i S i (即图中蓝色方块的划分方式)。
假设 x x x S i S_i S i m m m S i S_i S i
计算均值 (Mean):
μ = 1 m ∑ x ∈ S i x \mu = \frac{1}{m} \sum_{x \in S_i} x
μ = m 1 x ∈ S i ∑ x
计算方差 (Variance):
σ 2 = 1 m ∑ x ∈ S i ( x − μ ) 2 \sigma^2 = \frac{1}{m} \sum_{x \in S_i} (x - \mu)^2
σ 2 = m 1 x ∈ S i ∑ ( x − μ ) 2
标准化 (Normalize):
x ^ = x − μ σ 2 + ϵ \hat{x} = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}}
x ^ = σ 2 + ϵ x − μ
(其中 ϵ \epsilon ϵ
缩放和平移 (Scale and Shift - 仿射变换):
y = γ x ^ + β y = \gamma \hat{x} + \beta
y = γ x ^ + β
(其中 γ \gamma γ β \beta β
RMSNorm 的特例公式
RMSNorm 省略了上述的第 1 步和第 2 步,不再计算均值中心化,公式简化为:
计算均方根 (RMS):
R M S ( x ) = 1 m ∑ x ∈ S i x 2 + ϵ RMS(x) = \sqrt{\frac{1}{m} \sum_{x \in S_i} x^2 + \epsilon}
R M S ( x ) = m 1 x ∈ S i ∑ x 2 + ϵ
直接缩放:
y = γ x R M S ( x ) y = \gamma \frac{x}{RMS(x)}
y = γ R M S ( x ) x
(注:通常 RMSNorm 连偏置项 β \beta β γ \gamma γ
PyTorch 实现
为了加深理解,下面我们不调用 torch.nn 中现成的 BatchNorm2d 等 API,而是利用基本的张量操作(如 mean, var)来手动实现这五种归一化方法。
注:在 PyTorch 中使用 .var() 时,必须设置 unbiased=False,因为归一化算法中的方差计算使用的是有偏估计(分母为 m m m m − 1 m-1 m − 1
1. BatchNorm2d 实现 (CV视角)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import torchimport torch.nn as nnclass MyBatchNorm2d (nn.Module):def __init__ (self, num_features, eps=1e-5 ):super ().__init__()self .gamma = nn.Parameter(torch.ones(1 , num_features, 1 , 1 ))self .beta = nn.Parameter(torch.zeros(1 , num_features, 1 , 1 ))self .eps = epsdef forward (self, x ):0 , 2 , 3 ), keepdim=True )0 , 2 , 3 ), unbiased=False , keepdim=True )self .eps)return self .gamma * x_hat + self .beta
2. LayerNorm 实现 (NLP视角)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class MyLayerNormNLP (nn.Module):def __init__ (self, dim, eps=1e-5 ):super ().__init__()self .gamma = nn.Parameter(torch.ones(dim))self .beta = nn.Parameter(torch.zeros(dim))self .eps = epsdef forward (self, x ):1 , keepdim=True )1 , unbiased=False , keepdim=True )self .eps)return self .gamma * x_hat + self .beta
3. InstanceNorm 实现 (CV视角)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class MyInstanceNorm2d (nn.Module):def __init__ (self, num_features, eps=1e-5 ):super ().__init__()self .gamma = nn.Parameter(torch.ones(1 , num_features, 1 , 1 ))self .beta = nn.Parameter(torch.zeros(1 , num_features, 1 , 1 ))self .eps = epsdef forward (self, x ):2 , 3 ), keepdim=True )2 , 3 ), unbiased=False , keepdim=True )self .eps)return self .gamma * x_hat + self .beta
4. GroupNorm 实现 (CV视角)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class MyGroupNorm (nn.Module):def __init__ (self, num_groups, num_channels, eps=1e-5 ):super ().__init__()self .num_groups = num_groupsself .gamma = nn.Parameter(torch.ones(1 , num_channels, 1 , 1 ))self .beta = nn.Parameter(torch.zeros(1 , num_channels, 1 , 1 ))self .eps = epsdef forward (self, x ):self .num_groups, C // self .num_groups, H, W)2 , 3 , 4 ), keepdim=True )2 , 3 , 4 ), unbiased=False , keepdim=True )self .eps)return self .gamma * x_hat + self .beta
5. RMSNorm 实现 (NLP视角)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class MyRMSNorm (nn.Module):def __init__ (self, dim, eps=1e-6 ):super ().__init__()self .weight = nn.Parameter(torch.ones(dim))self .eps = epsdef forward (self, x ):pow (2 ).mean(dim=-1 , keepdim=True ) + self .eps)return self .weight * (x / rms)