论文一:掩码引导的缺陷图像生成
论文一:掩码引导的缺陷图像生成
题目: Free Lunch of Image-mask Alignment for Anomaly Image Generation and Segmentation
发表于: 2025年的IJCAI会议
作者: Xiangyue Li¹, Xiaoyang Wang², Zhibin Wan¹, Quan Zhang², Yupei Wu³, Tao Deng¹, Mingjie Sun¹*
¹苏州大学计算机科学与技术学院 ² 西安交通利物浦大学 ³ Aqrose Technology
摘要
本文旨在生成异常图像及其分割标签,以解决真实世界中异常样本稀缺问题。有别于传统方法仅将掩码(mask)作为引导图像生成的条件,本文提出了一种双分支训练策略(Dual-Branch Training Strategy):在扩散模型的训练阶段,同时学习生成异常图像和对应掩码,并引入对齐正则化损失(Alignment Regularization Loss)来确保生成图像与掩码在空间上的一致性。在推理阶段,仅激活图像生成分支产生合成样本,用以扩充下游分割模型的训练集。此外,本文进一步提出将训练好的生成模型整合进分割模型的训练过程中,利用生成反馈损失(Generative Feedback Loss)将扩散模型所学到的图像-掩码对齐知识"免费"迁移给分割模型,实现对分割性能的进一步提升。实验结果表明,本方法在 Real-IAD(工业缺陷)、Polyp(医疗内窥镜)和 Floor Dirty(室内污渍)三个数据集上的 IoU 指标分别比先前方法提升了 5.03%、5.68% 和 16.63%。
1. 研究背景与动机
1.1 任务定义
异常图像生成与分割(Anomaly Image Generation and Segmentation)的目标是:在一个统一的流程中,生成包含异常区域的图像(如工业产品缺陷、医疗影像中的病变组织),并同时输出其对应的像素级掩码标签。通过生成高质量的合成图像-掩码对,可以在无需真实异常样本的条件下训练性能优秀的分割模型。
1.2 主流方法的演进
早期方法(基于纹理迁移): Zavrtanik 等人(DRAEM, 2021)[5]尝试将已有的异常纹理粘贴到正常图像上,但生成结果真实感差、多样性不足。
GAN 方法: DefectGAN(Zhang et al., 2021)[6]利用生成对抗网络直接在正常样本上生成异常,但受限于 GAN 训练不稳定的特性,仅能利用有限的异常样本,生成质量受到制约。
扩散模型方法(当前主流): 以 AnomalyDiffusion(Hu et al., 2024)[2]和 ArSDM(Du et al., 2023)[1]为代表,利用扩散模型(Diffusion Model)强大的生成能力,基于掩码条件生成异常图像。AnomalyDiffusion 是本文最主要的对比基线,其流程如下:
- 先独立采样/生成异常掩码;
- 将掩码作为条件输入,引导扩散模型生成对应的异常图像;
- 用合成的图像-掩码对扩充训练集,训练下游分割模型。
1.3 现有方法的核心缺陷:标签漂移
上述掩码引导方法存在一个根本性问题——标签漂移。
扩散模型在生成异常图像时,本质上是以掩码作为"软引导"信号进行去噪,模型对掩码的理解较为粗糙(coarse understanding)。由于图像特征和掩码特征在 VAE 编码后处于不同的分布空间,二者之间存在分布差距(distribution gap),导致生成的图像与输入掩码在前景/背景边界上出现错位:
- 生成的异常区域可能超出掩码边界,或只覆盖掩码的一部分;
- 这样的错位图像-掩码对若直接用于训练分割模型,相当于提供了错误的监督信号(false supervision),反而会损害分割性能。
本文将这一问题归因于:在传统训练中,掩码仅作为条件(condition),而非去噪目标(denoising target),模型从未被显式地要求理解和生成准确的掩码边界,因此无法建立图像与掩码在像素级的精确对应关系。
2. 方法概述
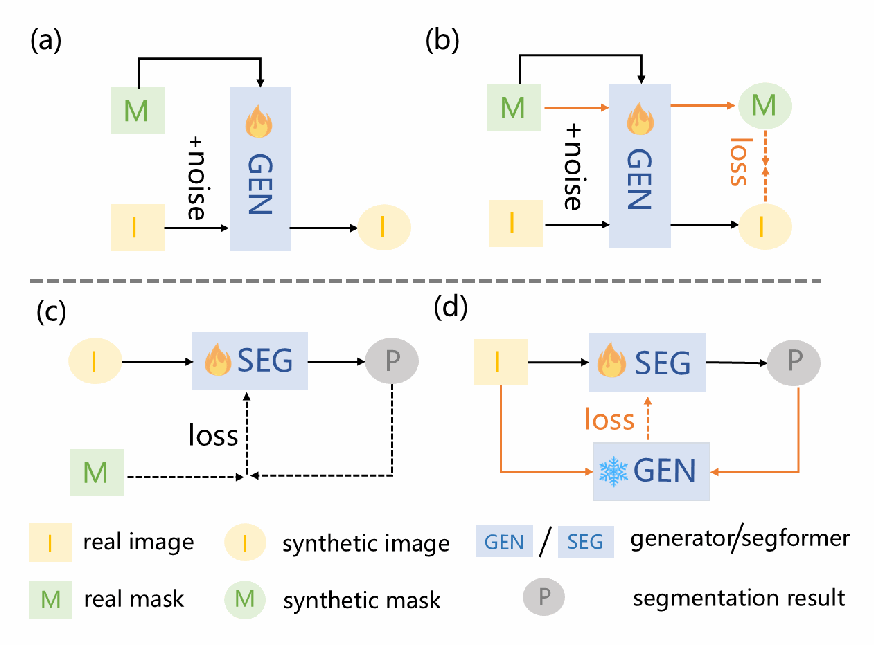
图1说明:
- (a) 先前的掩码引导生成方法:生成图像与掩码存在错位,即标签漂移问题(Label Drift);
- (b) 本文双分支策略:将掩码纳入噪声添加与去噪过程,引入对齐正则化,使图像与掩码特征分布趋于一致;
- © 先前方法的分割训练仅利用真实数据和合成数据,未挖掘扩散模型内部的图像-掩码对应知识;
- (d) 本文提出生成反馈(Generative Feedback),以扩散模型的生成目标直接评估分割预测,进一步提升分割性能。
本文方法由以下两个相互配合的核心模块构成:
2.1 整体框架
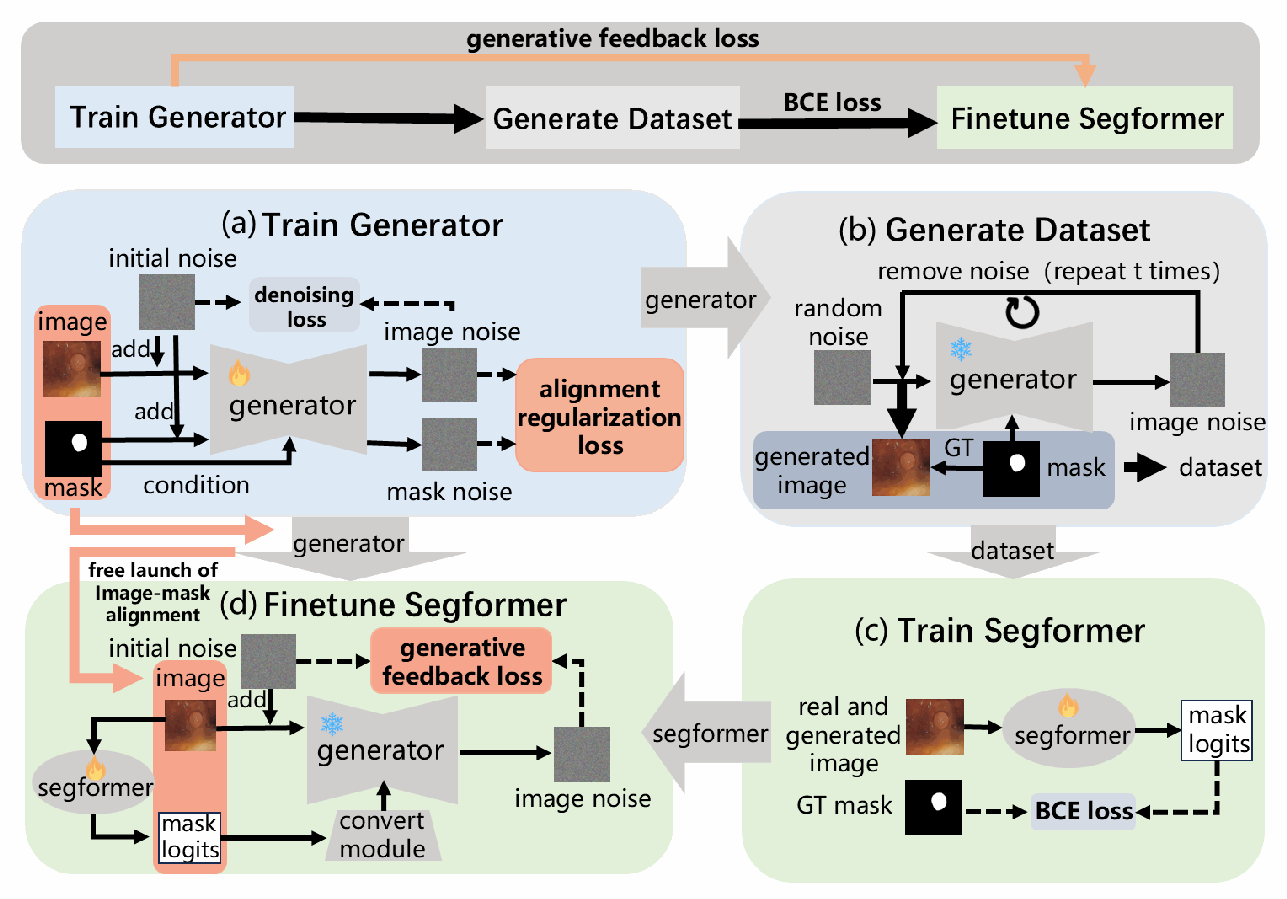
图2说明: 本文方法的整体四阶段流程:
(a) 双分支扩散模型训练:加入对齐正则化损失,使模型学习精确的图像-掩码对齐关系;
(b) 合成数据生成:利用已训练好的生成模型,基于真实掩码批量生成高质量合成异常图像,构建生成数据集;
© 扩充数据集的分割训练:将真实数据集与生成数据集合并,训练分割模型,增强其泛化能力;
(d) 生成反馈优化:借助扩散模型中学到的图像-掩码对齐知识,通过生成目标迭代细化分割模型的输出。
整个框架可以分为两个训练阶段:阶段一是对生成模型进行双分支微调;阶段二是在扩充数据集上训练分割模型,并引入生成反馈损失。
2.2 阶段一:双分支生成策略与对齐正则化
基础架构:潜在扩散模型(LDM)
本文以 Stable Diffusion(SD)为基础生成模型[3],其由以下核心组件构成:
| 组件 | 作用 |
|---|---|
| VAE 编码器 E | 将高分辨率图像 压缩为低维潜变量 |
| VAE 解码器 D | 将潜变量 还原为像素空间图像 |
| CLIP 文本编码器 | 将文本提示 编码为文本嵌入向量 |
| 调度器(Scheduler) | 控制前向扩散过程中噪声的添加节奏 |
| U-Net 去噪网络 | 在去噪过程中预测各时间步的噪声 |
模型同时以二值掩码 (指定异常区域位置)和文本描述 (提供内容上下文)为条件进行图像生成。标准的扩散模型训练损失(Equation 1)为:
即最小化去噪网络对实际噪声的预测误差(MSE)。
标签漂移的根本原因
在标准的掩码引导生成中,图像的潜变量 与掩码的潜变量 来自不同的 VAE 编码过程,由于异常图像与二值掩码在视觉上存在本质差异,二者编码后的特征分布之间存在天然的间隙(distribution gap)。这一分布差距使得模型难以学习有效的掩码-图像相关性,从而导致了标签漂移中的前景区域偏移(foreground drift)现象。
双分支训练策略
为解决上述问题,本文提出在扩散模型的训练过程中引入掩码去噪分支,使掩码不再仅仅作为条件,同时也成为模型需要预测的目标:
掩码编码与加噪:
其中,掩码 通过 VAE 编码器压缩为潜变量 ,然后与图像潜变量 采用完全相同的噪声 在相同的时间步 进行加噪,得到带噪掩码特征 。
双分支去噪与对齐正则化:
去噪网络分别对 (图像)和 (掩码)进行噪声预测,对齐正则化损失定义为两个分支噪声预测之间的差异:
最终生成模型的总训练损失为:
机制解析: 通过对图像和掩码施加相同的噪声并要求模型同时去噪,模型被显式地迫使在图像特征和掩码特征之间建立像素级的对应关系(explicit link)。掩码中的轮廓、边界等形状信息会通过对齐正则化损失传递到图像生成分支,从根本上缩小二者的分布差距,使生成的图像能够与掩码精确对齐。
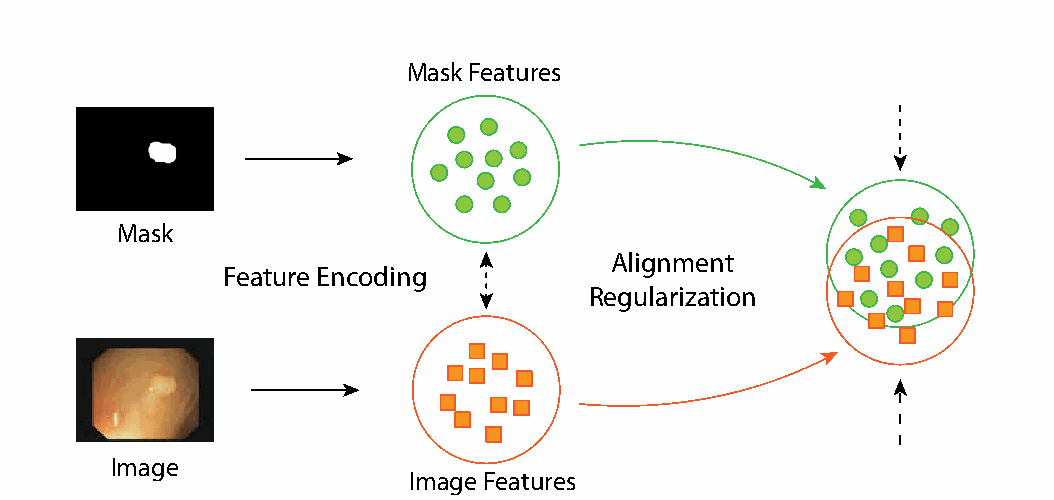
图3说明: 对齐正则化机制的工作原理。图中上路为掩码特征(Mask Features)分支,下路为图像特征(Image Features)分支。两路特征经过各自的特征编码(Feature Encoding)后,通过对齐正则化(Alignment Regularization)模块施加一致性约束。通过强制两支路的噪声预测保持一致,有效弥合了图像与掩码特征的分布差距,从而增强了掩码作为生成条件信号的有效性。
推理阶段: 双分支策略仅在训练时使用。推理时只激活图像生成分支,以真实掩码为条件,批量生成合成异常图像,与真实数据一起构建扩充训练集。
2.3 阶段二:生成反馈损失
核心洞察:“免费的午餐”
经过双分支微调的扩散模型,已经在内部建立了精确的图像-掩码对齐表示。本文的关键发现是:这种对齐知识可以被"免费地"迁移给分割模型——无需任何额外的人工标注,只需让分割模型的预测结果参与扩散模型的前向过程,即可利用扩散模型的生成损失作为分割的额外监督信号。
Figure 4:Logits 转换为近似掩码的模块
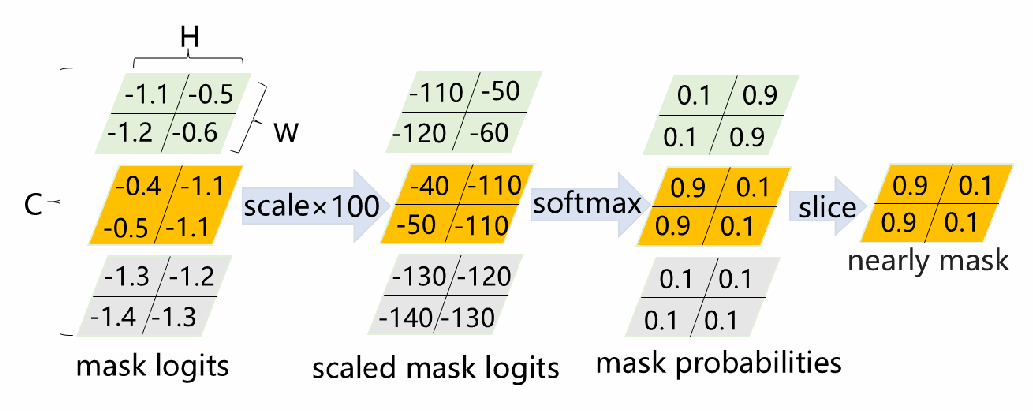
图4说明: 将分割模型输出的 logits 转换为近似二值掩码 的流程。对 logits 进行数值放大,再沿通道维度做带温度参数 的 Softmax,最后提取第二(前景)通道的概率值,得到图右侧黄色所示的概率热图作为近似掩码。该近似掩码再连同文本嵌入 一起输入扩散模型进行噪声预测。
近似掩码的生成
分割模型对输入图像产生预测 logits ,通过以下步骤得到近似二值掩码 :
- 数值放大: 对 logits 乘以温度系数 ,使输出更"锐利"(sharpening);
- Softmax 归一化: 沿通道维度进行 Softmax,得到各类别的概率分布;
- 前景提取: 截取第二通道(前景类)的预测概率,得到连续值近似掩码 。
生成反馈损失的计算
以近似掩码 和文本嵌入 为条件,已训练好的扩散模型对加噪后的图像潜变量 进行噪声预测,生成反馈损失 定义为:
分割模型最终的总损失为:
反馈机制的直觉理解
| 分割预测质量 | 扩散模型行为 | 对分割模型的作用 | |
|---|---|---|---|
| 预测掩码与真实掩码高度吻合 | 能以 为条件精确重建图像,噪声预测准确 | 低 | 正向激励,保持当前预测 |
| 预测掩码与真实掩码差异较大 | 以错误 为条件重建图像,噪声预测偏差大 | 高 | 负向惩罚,推动预测修正 |
这种机制将扩散模型在训练阶段习得的"什么样的掩码对应什么样的图像"的先验知识,以损失函数的形式直接注入分割模型的训练中,实现了两个模型之间的知识蒸馏(knowledge distillation)。
3. 实验设置
3.1 数据集
Polyp 数据集(医疗内窥镜)
结肠镜息肉分割数据集,由多个子集组成:
- 训练集: ClinicDB + Kvasir,共约 1,450 张图像
- 测试集: 包含 CVC-300、CVC-ClinicDB、Kvasir、CVC-ColonDB、ETIS、EndoScene 等多个子集
- 测试集中 ETIS 和 EndoScene 与训练集分布差异较大,是评估泛化能力的关键子集
Real-IAD 数据集(工业缺陷)
真实世界多视角工业异常检测数据集(Wang et al., CVPR 2024)[4]:
- 包含 30 种工业零件,分为简单(10 类,easy)和困难(20 类,hard)两个子集
- 同时在 MvTec-AD 上进行了对比实验
Floor Dirty 数据集(室内环境)
地面污渍检测数据集,用于验证方法在室内场景的泛化能力。
3.2 评估指标
| 指标 | 含义 | 越大/小越好 |
|---|---|---|
| mIoU | 平均交并比,衡量分割精度 | 越大越好 |
| mDice | Dice 系数,衡量分割精度 | 越大越好 |
| FID | Fréchet Inception Distance,衡量生成图像与真实图像的分布距离 | 越小越好 |
| IS | Inception Score,衡量生成图像的质量与多样性 | 越大越好 |
| LPIPS | 感知图像相似度[7],衡量生成图像的感知质量 | 越小越好 |
4. 实验结果
4.1 Polyp 生成图像质量对比

图5说明: 在 Polyp 数据集上,对 VAE 编码后的图像特征进行 t-SNE 降维可视化,展示不同类型异常样本的特征分布。本文方法生成的合成样本(橙色点)在特征空间中与真实样本(蓝色点)分布更为接近且重叠度更高,说明双分支对齐策略有效提升了生成样本的真实感,使其能够为分割模型提供更有价值的训练信号。
| 方法 | FID ↓ | IS ↑ | LPIPS ↓ |
|---|---|---|---|
| ArSDM | 361.55 | 1.98 | 0.869 |
| Ours | 162.01 | 3.25 | 0.698 |
本文方法在 FID 上降低了约 55%,IS 提升约 64%,LPIPS 降低约 20%,全面优于基线方法 ArSDM,验证了双分支对齐策略对生成质量的显著提升。
4.2 Polyp 分割性能对比
| 方法 | 主干 | 训练数据量 | CVC-300 mIoU | ClinicDB mIoU | Kvasir mIoU | ColonDB mIoU | ETIS mIoU | Avg mIoU | Avg mDice |
|---|---|---|---|---|---|---|---|---|---|
| 基础 | PVT-v2 | real (100) | — | — | — | — | — | — | — |
| +ArSDM | PVT-v2 | 1450 | 92.2 | 87.5 | 80.6 | 72.9 | 88.2 | 86.84 | 80.34 |
| 基础 | SANet | real (1450) | 91.6 | 85.9 | 75.0 | 65.4 | 88.8 | 84.22 | 76.76 |
| +real | SANet | 1450 | 92.2 | 87.2 | 78.3 | 69.8 | 88.6 | 84.98 | 78.44 |
| +ArSDM | SANet | 1450 | 91.4 | 86.1 | 78.0 | 69.5 | 90.2 | 85.68 | 78.88 |
| 基础 | Segformer | real (100) | 84.6 | 76.8 | 71.2 | 64.5 | 87.3 | 81.20 | 73.65 |
| +ArSDM | Segformer | 1450 | 88.7 | 82.0 | 73.9 | 66.7 | 85.7 | 82.96 | 75.66 |
| +Ours | Segformer | 1450 | 93.2 | 88.3 | 81.8 | 74.4 | 92.0 | 87.59 | 81.34 |
本文方法在 Segformer 骨干下取得最优结果(加粗),尤其在 ETIS 和 EndoScene 等与训练集分布差异较大的测试集上提升显著,体现了更强的泛化能力。
4.3 工业异常分割性能对比
| 数据集 | 方法 | 平均 mIoU |
|---|---|---|
| MvTec-AD | AnomalyDiffusion | baseline |
| MvTec-AD | Ours | +1.07% |
| Real-IAD (Easy) | AnomalyDiffusion | baseline |
| Real-IAD (Easy) | Ours | +5.03% |
| Floor Dirty | AnomalyDiffusion | baseline |
| Floor Dirty | Ours | +16.63% |
在 Floor Dirty 数据集上提升尤为显著(+16.63%),说明本方法对训练-测试集分布差异较大的场景具有更强的适应性。
4.4 总体生成质量结果对比
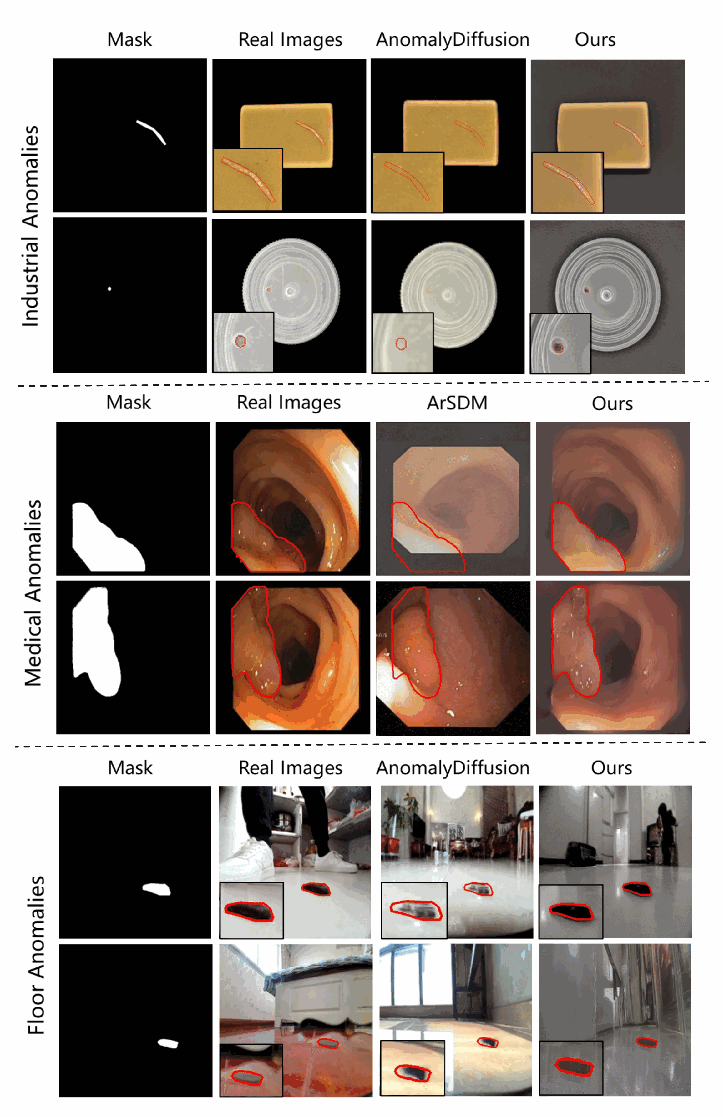
图6说明: 多个数据集上各方法分割结果的视觉对比。列从左至右依次为:输入图像、真实标注掩码(GT)、仅使用真实数据训练的 baseline、使用 ArSDM 合成数据训练的结果、以及本文方法的预测结果。
可以观察到:在息肉边缘细节处、以及训练集外分布的图像上,本文方法的分割轮廓明显更贴近真实标注,ArSDM 方法在部分样本上出现边界错位或漏检,而本文方法能够更准确地定位和描绘异常区域的完整轮廓。
5. 消融实验
5.1 各核心组件的贡献
| 配置 | mIoU (%) | ||
|---|---|---|---|
| Baseline(仅真实数据) | ✗ | ✗ | 78.80 |
| + 对齐正则化损失 | ✓ | ✗ | 80.xx |
| + 生成反馈损失 | ✗ | ✓ | 79.xx |
| 完整方法(两者均有) | ✓ | ✓ | 82.22 |
两个组件均对最终性能有独立的正向贡献,结合使用时效果最优,从 78.80% 提升至 82.22%(+3.42%)。
5.2 真实掩码数量对生成效果的影响
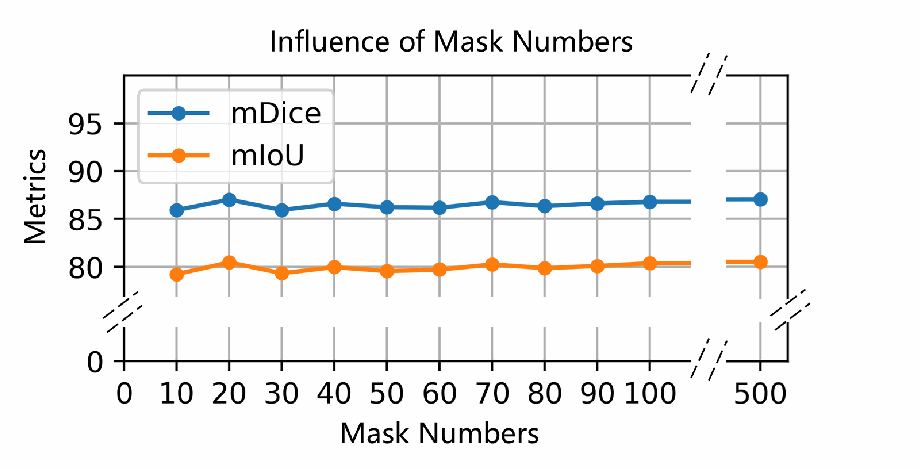
图7说明: 用于引导合成样本生成的真实掩码数量(x轴)与下游分割模型 mIoU(y轴)之间的关系曲线。实验表明两者呈非线性关系:
- 使用 20 个掩码时,mIoU 达到峰值 80.47%;
- 使用 10 个掩码时,mIoU 最低为 79.24%;
- 从 60 到 100 个掩码,mIoU 小幅增至 80.38%;
- 极端情况下仅用 20 个样本微调扩散模型时,mIoU 下降至 47.27%,说明扩散模型需要一定量的样本以充分学习图像-掩码对应关系。
总体而言,本文方法对真实掩码数量的变化不敏感,仅需少量真实掩码即可取得良好的合成效果,体现了较强的鲁棒性。
6. 核心创新点总结
| 创新点 | 解决的问题 | 技术手段 | 效果 |
|---|---|---|---|
| 双分支生成训练策略 | 标签漂移(Label Drift) | 将掩码纳入噪声添加与去噪过程,与图像同步训练 | FID 降低 55%,合成质量大幅提升 |
| 对齐正则化损失 | 图像-掩码特征分布差距 | 约束双分支噪声预测的一致性,建立像素级对应 | 独立贡献约 +1-2% mIoU |
| 生成反馈损失 | 生成模型对齐知识未被充分利用 | 以分割预测的近似掩码为条件计算生成误差,监督分割 | 独立贡献约 +1-2% mIoU,两者叠加 +3.42% |
"Free Lunch"的完整含义
本文标题中的"免费午餐"(Free Lunch)体现在两个层面:
-
生成阶段的 Free Lunch: 通过双分支训练,在优化图像生成质量的同时,“顺带”(free)习得了精确的掩码生成能力,且在推理阶段不引入任何额外计算开销(仅激活图像生成分支);
-
分割阶段的 Free Lunch: 通过生成反馈,将扩散模型已经学到的对齐知识"免费"(free,无需额外标注)迁移给分割模型,只需改变损失函数即可提升分割精度,不引入额外的推理成本。
7. 相关工作
7.1 异常图像生成方法演进
| 方法类别 | 代表性工作 | 优点 | 缺点 |
|---|---|---|---|
| 纹理迁移 | DRAEM, Cut-Paste | 简单高效 | 真实感差、多样性低 |
| GAN 方法 | SDGAN, DefectGAN | 生成质量较好 | 训练不稳定,对样本量要求高 |
| 扩散模型 | AnomalyDiffusion, ArSDM | 高质量、多样性强 | 存在标签漂移问题 |
| 本文方法 | 双分支对齐扩散 | 高质量 + 精确对齐 | 训练流程相对复杂 |
7.2 异常图像分割
- PVT-v2(Dong et al., 2021)[8]:基于金字塔视觉 Transformer 的密集预测框架,是目前息肉分割的强力基线;
- SANet(Wei et al., 2021)[9]:结构感知网络,专为息肉分割设计,引入了结构先验;
- Segformer(Xie et al., 2021)[10]:轻量高效的 Transformer 分割架构,在多个分割任务上取得 SOTA。
7.3 扩散模型基础
- LDM(Latent Diffusion Model)(Rombach et al., CVPR 2022)[3]:将扩散过程迁移到 VAE 的潜变量空间,大幅降低计算量,是 Stable Diffusion 的核心框架;
- CLIP(Radford et al., ICML 2021)[11]:跨模态视觉-语言预训练模型,提供文本条件编码;
- U-Net(Ronneberger et al., 2015)[12]:编码器-解码器结构的分割网络,被 LDM 用作去噪主干网络。
参考
- Du, Y., et al. (2023). ArSDM: Colonoscopy Images Synthesis with Adaptive Refinement Semantic Diffusion Models. MICCAI 2023. ↩
- Hu, J., et al. (2024). AnomalyDiffusion: Few-Shot Anomaly Image Generation with Diffusion Model. AAAI 2024. ↩
- Rombach, R., et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022. ↩
- Wang, Y., et al. (2024). Real-IAD: A Real-World Multi-View Dataset for Benchmarking Versatile Industrial Anomaly Detection. CVPR 2024. ↩
- Zavrtanik, V., et al. (2021). DRAEM - A Discriminatively Trained Reconstruction Embedding for Surface Anomaly Detection. ICCV 2021. ↩
- Zhang, Z., et al. (2021). DefectGAN: High-Fidelity Defect Synthesis for Automated Defect Inspection. WACV 2021. ↩
- Zhang, R., et al. (2018). The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. CVPR 2018. ↩
- Dong, Y., et al. (2021). PVT v2: Improved Baselines with Pyramid Vision Transformer. arXiv preprint arXiv:2106.13797. ↩
- Wei, Y., et al. (2021). SANet: Structure-Aware Network for Polyp Segmentation. MICCAI 2021. ↩
- Xie, E., et al. (2021). SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. NeurIPS 2021. ↩
- Radford, A., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. ICML 2021. ↩
- Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. MICCAI 2015. ↩