论文二:融合缺陷检索和缺陷生成
论文二:缺陷检索和缺陷生成
发表于: CVPR 2026 Findings
作者: Xiangyue Li*(苏州大学), Xiaoyang Wang*(上海人工智能实验室), Siyue Yao*(西交利物浦大学), Mingjie Sun†(苏州大学 / 追觅科技), Yupei Wu(Aqrose Technology)
摘要
传统异常数据生成方法仅能针对特定对象生成特定类型的异常,无法充分利用历史异常数据,因此不能在工业生产中生成从未出现过的异常类型。
为克服上述局限,本文提出 Anomaly Agent 框架,由两个智能体协作完成"生产前异常数据准备"的全流程:
- 异常参考检索智能体(Anomaly Reference Retrieval Agent): 利用大型语言模型(LLM)和异常感知 CLIP(Anomaly-aware CLIP)进行跨模态检索,将产品名称映射到历史异常图像库中的相关异常图像,指出潜在异常类型;
- 统一异常合成智能体(Unified Anomaly Synthesis Agent): 以检索到的历史异常图像为参考,利用扩散模型生成目标产品的合成异常图像,并借助**保真度梯度细化(Fidelity Gradient Refinement)和真实性-保真度控制器(Plausibility-Fidelity Controller)**平衡生成异常的真实性与参考保真度。
在 MVTec-AD 数据集上的实验表明,本方法使像素级平均精度(AP)提升了 6.2%,显著超越现有方法。
1. 研究背景与动机
1.1 任务定义与挑战
工业异常检测(Industrial Anomaly Detection)要求在现代生产系统中精确、及时地识别偏离正常模式的微小缺陷。该任务面临极度的数据不平衡:正常样本在生产数据中占据绝对主导,异常样本极为稀少。
为缓解这一困难,研究者们提出利用数据增强和生成模型合成异常数据来显著提升检测精度[1][2]。
1.2 传统方法的三大缺陷
现有异常数据生成方法普遍遵循一个固定流程:先从生产过程中收集现有异常样本,再以这些样本训练生成模型产生合成异常数据。该流程存在以下关键限制:
缺陷一:依赖已知异常,无法"预见"新异常
传统方法需要等到实际生产阶段才能收集到目标产品的异常样本,对于新产品上线前(pre-manufacturing)的阶段无法提前准备异常数据。换言之,无法生成"从未出现过"的异常。
缺陷二:历史数据利用率低下
企业和研究机构往往积累了大量来自不同产品和类别的历史异常图像,但传统方法无法跨产品迁移这些知识,造成严重的数据浪费。
缺陷三:每类对象需单独训练生成模型
传统生成方法需要为每种异常类别单独训练生成模型,在产品种类繁多的实际工厂场景中,训练和维护成本极高,可扩展性(scalability)很差。
1.3 核心洞察
本文的核心思路是:将历史异常图像库当作"知识库"(knowledge base),通过智能检索将其中与目标产品最相关的异常迁移到新产品上。 这样既无需目标产品的异常样本,也无需为每个类别单独训练生成模型,实现了真正意义上的"生产前异常合成"。
2. 方法概述
2.1 和之前方法的对比
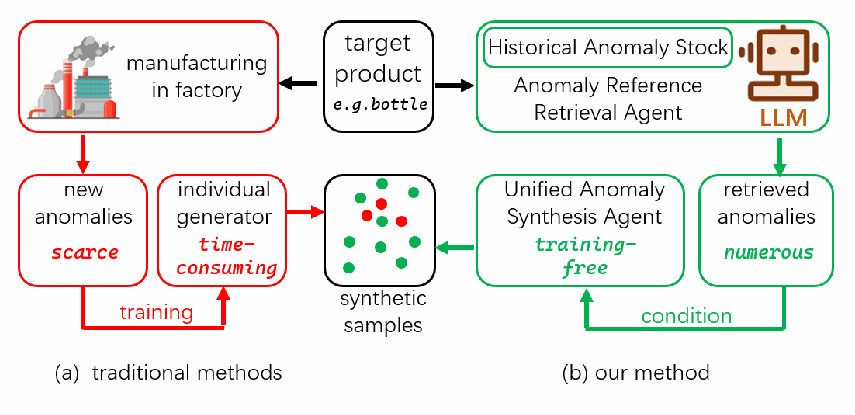
(a) 传统方法:严重依赖在目标产品生产阶段收集的稀缺异常数据,需为每类异常单独训练生成模型,且无法在生产前生成未知异常;(b) Anomaly Agent:可在生产前即生成目标产品的异常图像,使用统一模型进行异常合成(无需单独训练),整个生成过程无需训练(training-free),并能生成更加多样化的合成异常图像。
2.2 整体框架
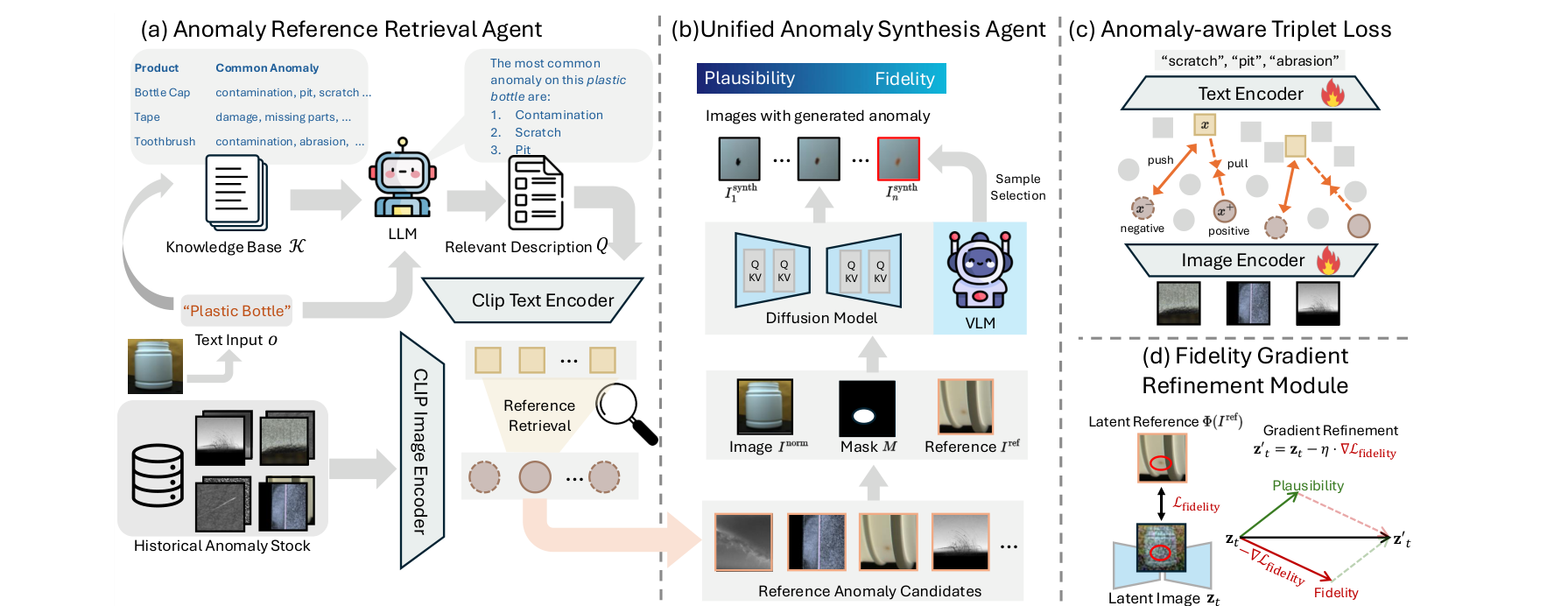
整体框架由四部分组成:(a) 异常参考检索智能体:接收目标对象名称(如 “Plastic Bottle”),通过 LLM + Anomaly-aware CLIP 在历史异常图像库中检索最相关的参考异常图像;(b) 统一异常合成智能体:以检索到的参考图像和正常产品图像为输入,通过扩散模型 + VLM 采样选择,生成目标产品的合成异常图像;© Anomaly-aware Triplet Loss:用于微调 CLIP 图像编码器,增强其对异常区域的感知能力;(d) 保真度梯度细化模块(Fidelity Gradient Refinement):在扩散推理阶段对潜变量施加梯度约束,在真实性(Plausibility)与保真度(Fidelity)之间动态平衡。
整个框架包含两个串联的智能体模块:
2.3 模块一:异常参考检索智能体
核心挑战:跨模态检索
检索问题的输入是文本形式的目标产品名称(如 “bottle”、“cable”),输出是历史图像库中视觉相关的异常图像。这是一个跨模态(文本→图像)的检索任务,且难度在于:一个产品名称可以对应多种异常类型,需要 LLM 的语义推理能力来桥接文本与图像之间的语义差距。
两阶段检索流程
第一阶段:LLM 驱动的文本-文本检索
首先以 GPT-4o[3] 作为 LLM,利用检索增强生成(RAG)[4] 技术,在由 Real-IAD[5] 数据集对象文本构成的知识库中,通过语义推理为目标产品名称匹配最相关的历史异常类型描述。具体来说:
- LLM 根据目标产品名称,推理该产品可能出现的异常类型(如腐蚀、划痕、孔洞);
- 同时检索知识库,找到历史数据中语义相近的异常描述。
第二阶段:Anomaly-aware CLIP 的文本-图像检索
以第一阶段得到的异常类型描述为查询,利用经过异常感知微调的 CLIP[6] 模型,在历史异常图像库中进行跨模态相似度匹配,检索出视觉上最匹配的参考异常图像。
检索结果的 GPT-4o 质量评估
对于每张检索到的候选异常图像,进一步用 GPT-4o 的多模态理解能力进行质量评估:
- 先询问 GPT-4o:“哪类对象可能具有该异常图像所示的缺陷?”
- 计算 GPT-4o 预测的对象名称与目标产品名称之间的 CLIP 相似度作为匹配得分;
- 取多张检索图像的平均匹配得分作为最终评估指标。
2.4 模块二:统一异常合成智能体
基础架构:无训练的扩散模型推理
本框架基于预训练的潜在扩散模型(LDM)[7],整个异常合成过程无需针对目标产品进行任何微调或训练,充分利用了扩散模型强大的生成先验(generative prior)。
核心思路是:将参考异常图像的视觉特征通过编码器 压缩为特征嵌入,然后利用自定义文本嵌入(基于 ELITE[8])将其与文本条件结合,引导扩散模型在目标产品正常图像上生成对应位置和外观的异常区域。
自定义文本嵌入:
以参考异常图像编码 为输入,通过 ELITE 映射网络优化文本嵌入 ,使该嵌入能够描述参考异常的视觉特征,随后作为扩散模型的文本条件注入生成过程。
异常掩码引导生成:
以异常掩码 为空间约束,生成过程仅在掩码指定的区域内进行异常合成,掩码之外区域保持原始正常图像不变,保证生成结果的空间一致性。
保真度梯度细化模块(Fidelity Gradient Refinement)
问题背景: 即便使用了参考异常的文本嵌入,扩散模型在推理时仍会受到自身生成先验的影响,可能产生视觉上不够忠实于参考异常的结果(即只学到了异常"类型",而非具体视觉细节)。
解决方案: 在每一步去噪推理时,引入基于梯度的引导(gradient guidance),将当前去噪潜变量 拉向参考异常特征方向。
保真度损失:
即当前去噪结果在掩码区域内与参考异常编码特征的 L2 距离。
潜变量更新:
在每步去噪后,沿梯度方向以步长 更新潜变量,将其拉向参考异常的特征分布。参数 控制细化强度,直接影响参考保真度与生成真实性之间的权衡。
真实性-保真度控制器(Plausibility-Fidelity Controller)
问题背景: 参数 是一个关键超参数—— 过小则合成结果偏离参考异常太远(仅保留了大致类型,丢失细节), 过大则会引入视觉伪影(artifacts),损害真实性(plausibility)。对每个样本手动调节 是不可行的。
解决方案: 引入视觉语言模型(VLM)作为自动控制器,动态评估当前生成结果的真实性,并据此调整 值:
- VLM 打分: 在去噪过程的中间步骤,利用 VLM 对当前去噪结果的异常区域进行真实性评估(即:该区域在目标产品上看起来是否合理?);
- 动态调整: 若 VLM 判断当前生成真实性较高,可适当增大 以提升保真度;若 VLM 判断真实性已受损,则降低 ,让模型先验起更大作用。
这一自适应控制策略使框架无需手动调参,在不同对象和异常类型上均能自动找到保真度与真实性的最优平衡点。
3. 实验设置
3.1 数据集
MVTec-AD 数据集(工业异常检测基准)
MVTec-AD[1] 是工业异常检测领域最广泛使用的标准基准,包含 15 类工业产品(纹理类和结构类),每类包含正常图像(训练集)和多种类型的异常图像(测试集)。本文以 MVTec-AD 作为下游异常检测任务的评估集。
Real-IAD 数据集(历史异常知识库)
Real-IAD[5] 是一个真实世界多视角工业异常检测数据集,包含 30 种工业零件及其对应的异常图像。在本框架中,Real-IAD 被用作历史异常图像知识库:
- 对象文本信息构成检索智能体的知识库文本索引;
- 所有异常图像构成可供检索的历史异常图像池;
- 为确保评估公正,MVTec-AD 的测试集数据在整个检索和生成过程中从未被触碰,彻底避免数据泄漏。
3.2 评估指标
| 指标 | 含义 | 越大/小越好 |
|---|---|---|
| Pixel-AP | 像素级平均精度(Average Precision),综合衡量异常区域定位精度 | 越大越好 |
| F₁-max | 最优 F₁ 分数 | 越大越好 |
| AUPRO | 每区域曲线下面积(Per-Region Overlap AUC),衡量细粒度定位 | 越大越好 |
| Pixel-AUROC | 像素级 ROC 曲线下面积 | 越大越好 |
| Image-AUROC | 图像级 ROC 曲线下面积,衡量图像级异常分类 | 越大越好 |
| Image-AP | 图像级平均精度 | 越大越好 |
| FID | Fréchet Inception Distance,衡量合成图像与真实图像的分布距离[9] | 越小越好 |
| LPIPS | 感知图像块相似度,衡量合成图像的感知质量[10] | 越小越好 |
4. 实验结果
4.1 异常检测性能对比(MVTec-AD)
| 方法 | 发表 | Pixel-AP↑ | F₁-max↑ | AUPRO↑ | Pixel-AUROC↑ | Image-AP↑ | Image-AUROC↑ |
|---|---|---|---|---|---|---|---|
| RD4AD[11] | CVPR22 | 48.6 | 53.8 | 91.1 | 96.1 | 96.5 | 94.6 |
| SimpleNet[12] | CVPR23 | 45.9 | 49.7 | 86.5 | 96.9 | 98.4 | 95.3 |
| DeSTSeg[13] | CVPR23 | 54.3 | 50.9 | 64.8 | 93.1 | 95.5 | 89.2 |
| UniAD[14] | NeurIPS22 | 43.4 | 49.5 | 90.7 | 96.8 | 98.8 | 96.5 |
| ReContrast[15] | NeurIPS23 | 60.2 | 61.5 | 93.2 | 97.1 | 99.4 | 98.3 |
| DiAD[16] | AAAI24 | 52.6 | 55.5 | 90.7 | 96.8 | 99.0 | 97.2 |
| ViTAD[17] | arXiv23 | 55.3 | 58.7 | 91.4 | 97.7 | 99.4 | 98.3 |
| MambaAD[18] | NeurIPS24 | 56.3 | 59.2 | 93.1 | 97.7 | 99.6 | 98.6 |
| Ours | — | 66.4 | 65.9 | 94.8 | 98.5 | 99.7 | 99.0 |
本方法在像素级 AP 上达到 66.4%,比第二名 ReContrast(60.2%)高出 6.2 个百分点,在所有指标上均取得最优结果。
4.2 合成图像多样性对比

图3说明: 本方法与 AnomalyDiffusion[19] 的合成多样性对比。AnomalyDiffusion 只能生成 MVTec-AD 数据集中已有的有限异常类别;而 Anomaly Agent 通过检索 Real-IAD 历史异常库,可以为目标对象提供更多样、更丰富的异常类别参考,合成结果涵盖了真实生产中更广泛的异常类型。
4.3 Anomaly-aware CLIP的缺陷检测

经过缺陷数据微调后,CLIP变为Anomaly-aware CLIP,能够识别和定位图像中的缺陷。第一列为缺陷图像,第二列为原始的CLIP进行缺陷检测的热力图,第三列为微调后的Anomaly-aware CLIP进行缺陷检测的热力图。
4.4 生成图像的真实性和保真度

针对不同偏好的生成图像的展示。第一列为参考图像,第二列为生成图像(真实性更强, 数值低),第三列为生成图像(保真度更强,和参考图像更相似, 数值高)。
5. 消融实验
5.1 各模块的独立贡献
| 配置 | Pixel-AP↑ | AUPRO↑ |
|---|---|---|
| Baseline(仅使用正常图像训练) | — | — |
| + 异常参考检索(无合成) | — | — |
| + 合成(无梯度细化) | 62.1 | 93.5 |
| + 保真度梯度细化 | 65.0 | 94.5 |
| + 真实性-保真度控制器(完整方法) | 66.4 | 94.8 |
每个模块均对最终性能有独立的正向贡献,完整框架效果最优。
5.2 参数 η 的影响
实验表明,固定 值对不同对象和异常类型的效果差异显著:
- 过低(如 0.01):合成异常过于"平庸",与参考异常相似度低;
- 过高(如 0.5):合成图像出现明显伪影,真实性受损;
- 真实性-保真度控制器的自动调节在各类别上均能找到较好的平衡点。
6. 核心创新点总结
| 创新点 | 解决的问题 | 技术手段 | 效果 |
|---|---|---|---|
| 异常参考检索智能体 | 历史数据利用不足、无法预见未知异常 | LLM + Anomaly-aware CLIP 跨模态检索 | 实现生产前异常多样化合成 |
| 统一异常合成智能体(无训练) | 每类需单独训练生成模型 | 基于预训练 LDM 的 training-free 推理 | 统一模型覆盖所有对象类别 |
| 保真度梯度细化 | 合成异常与参考视觉差异大 | 去噪过程中引入梯度引导拉近特征距离 | 合成质量显著提升 |
| 真实性-保真度控制器 | η 手动调参困难 | VLM 动态评估并自动调节 η | 全自动无需手工调参 |
"Before Manufacturing"的深层含义
本文标题中的"Before Manufacturing"(生产前)强调了方法的核心价值:在目标产品进入实际生产线之前,即可利用历史异常知识库完成异常数据准备工作,使下游检测模型能够提前训练并部署,而非等待生产阶段缓慢积累异常样本。
这一思路将传统的"先收集→再训练→再检测"的被动流程,转变为"先检索→先合成→先训练"的主动流程,对于快速迭代的现代智能制造场景具有重要的实际意义。
7. 相关工作
7.1 异常数据生成方法
| 方法类别 | 代表性工作 | 优点 | 缺点 |
|---|---|---|---|
| 纹理粘贴 | DRAEM[20], Cut-Paste | 简单直接 | 真实感差,多样性低 |
| GAN 生成 | DefectGAN[21] | 质量较好 | 每类需独立训练,可扩展性差 |
| 扩散模型(单一数据集) | AnomalyDiffusion[19] | 高质量 | 局限于已知异常类别 |
| 本文方法(跨数据集迁移) | Anomaly Agent | 多样性强、无需训练 | 检索质量依赖知识库规模 |
7.2 基础模型
- LDM(Latent Diffusion Model)(Rombach et al., CVPR 2022)[7]:将扩散过程迁移到 VAE 潜变量空间,大幅降低计算量,是 Stable Diffusion 的核心框架;
- CLIP(Radford et al., ICML 2021)[6]:跨模态视觉-语言预训练模型,提供文本-图像相似度度量;
- GPT-4o(OpenAI, 2024)[3]:多模态大语言模型,提供视觉问答和语义推理能力;
- ELITE(Wei et al., ICCV 2023)[8]:将视觉概念编码为文本嵌入,支持定制化文本引导图像生成;
- RAG(Retrieval-Augmented Generation)[4]:通过外部知识库增强 LLM 的检索和推理能力。
7.3 异常检测框架
- RD4AD[11]:利用反向蒸馏(reverse distillation)进行单类别异常检测;
- UniAD[14]:统一多类别异常检测模型;
- MambaAD[18]:基于 Mamba 状态空间模型的高效异常检测方法。
参考
- Bergmann, P., et al. (2019). MVTec AD — A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. CVPR 2019. ↩
- Hu, J., et al. (2024). AnomalyDiffusion: Few-Shot Anomaly Image Generation with Diffusion Model. AAAI 2024. ↩
- OpenAI. (2024). GPT-4o Technical Report. OpenAI. ↩
- Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020. ↩
- Wang, C., et al. (2024). Real-IAD: A Real-World Multi-View Dataset for Benchmarking Versatile Industrial Anomaly Detection. CVPR 2024. ↩
- Radford, A., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. ICML 2021. ↩
- Rombach, R., et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022. ↩
- Wei, Y., et al. (2023). ELITE: Encoding Visual Concepts into Textual Embeddings for Customized Text-to-Image Generation. ICCV 2023. ↩
- Heusel, M., et al. (2017). GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. NeurIPS 2017. ↩
- Zhang, R., et al. (2018). The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. CVPR 2018. ↩
- Deng, H., & Li, X. (2022). Anomaly Detection via Reverse Distillation from One-Class Embedding. CVPR 2022. ↩
- Liu, Z., et al. (2023). SimpleNet: A Simple Network for Image Anomaly Detection and Localization. CVPR 2023. ↩
- Zhang, X., et al. (2023). DeSTSeg: Segmentation Guided Denoising Student-Teacher for Anomaly Detection. CVPR 2023. ↩
- You, Z., et al. (2022). A Unified Model for Multi-Class Anomaly Detection. NeurIPS 2022. ↩
- Guo, J., et al. (2023). ReContrast: Domain-Specific Anomaly Detection via Contrastive Reconstruction. NeurIPS 2023. ↩
- He, Y., et al. (2024). DiAD: A Diffusion-Based Framework for Multi-Class Anomaly Detection. AAAI 2024. ↩
- Zhu, Y., et al. (2023). ViTAD: Vision Transformer for Unsupervised Anomaly Detection. arXiv 2023. ↩
- He, J., et al. (2024). MambaAD: Exploring State Space Models for Multi-Class Unsupervised Anomaly Detection. NeurIPS 2024. ↩
- Hu, J., et al. (2024). AnomalyDiffusion: Few-Shot Anomaly Image Generation with Diffusion Model. AAAI 2024. ↩
- Zavrtanik, V., et al. (2021). DRAEM - A Discriminatively Trained Reconstruction Embedding for Surface Anomaly Detection. ICCV 2021. ↩
- Zhang, G., et al. (2021). DefectGAN: High-Fidelity Defect Synthesis for Automated Defect Inspection. WACV 2021. ↩