FLUX.1-dev架构分析
FLUX.1-dev 架构详解
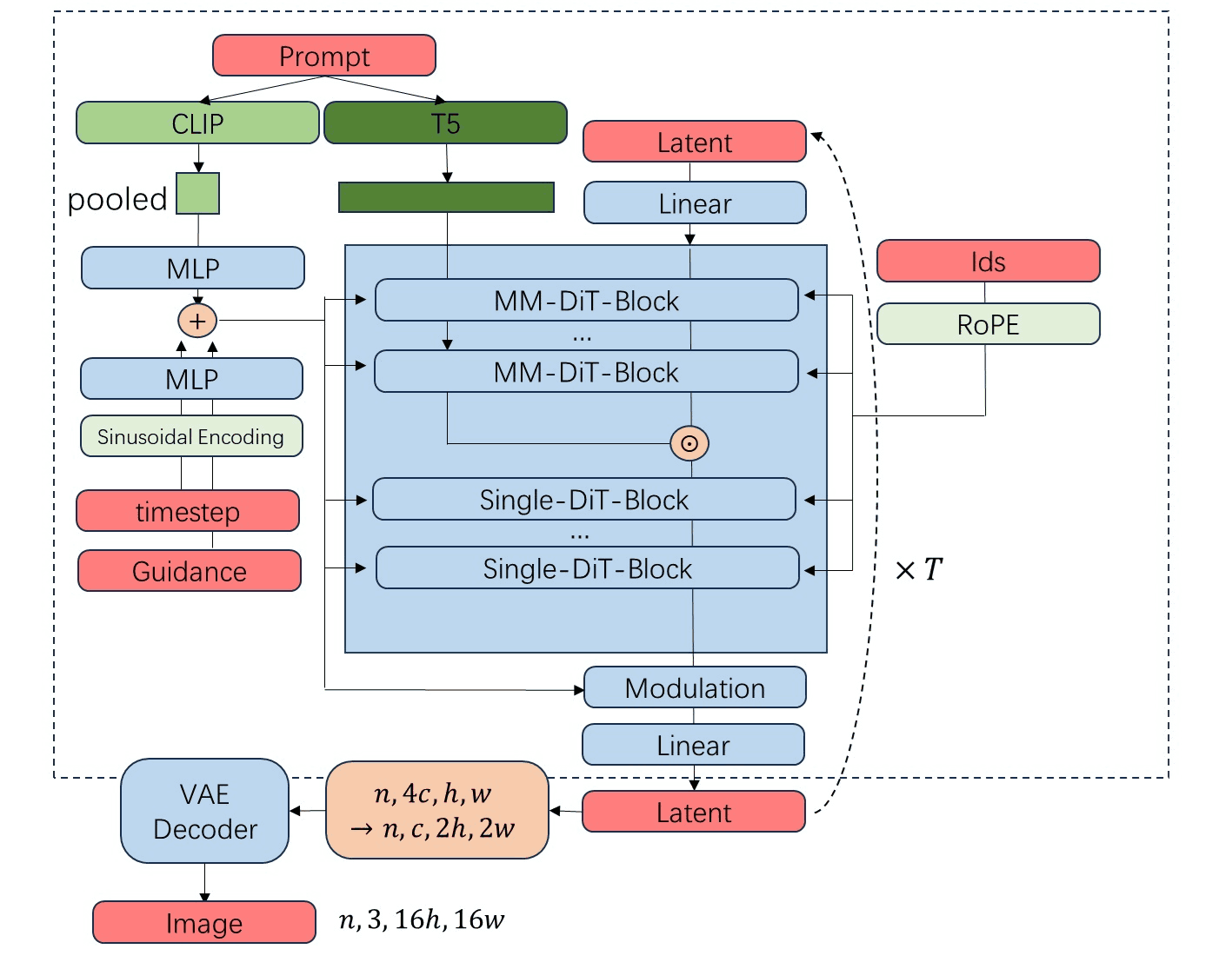
FLUX.1(由 Black Forest Labs 发布)是当前开源图像生成领域的顶级模型。FLUX.1 并没有完全沿用 SD3 的 MMDiT,而是在 DiT 的基础上引入了 混合架构 (Hybrid Architecture),并全面使用了流匹配(Flow Matching)与多维度旋转位置编码(RoPE),展现了对极其复杂的图文理解与极高画质的统治力。
- 混合双流与单流架构 (Double-Stream & Single-Stream):FLUX 认为在早期阶段,图像和文本特征需要独立对齐(双流);但在网络深层,它们需要被当作同等级别的信息进行极限融合(单流)。因此模型前段使用双流块(独立 FFN/Norm + 联合 Attention),后段直接将文本和图像拼接为一个序列输入单流块(统一 Attention + 统一 FFN)。
- 多维旋转位置编码 (Rotary Positional Embeddings, RoPE):抛弃了传统的绝对正弦波位置编码或可学习位置编码。FLUX 对图像 Patch 序列和文本序列均在每一层 Attention 中施加 RoPE(针对图像专门设计了 2D RoPE),极大提升了模型对空间位置的感知能力和任意分辨率的泛化能力。
- 指引蒸馏与流匹配 (Guidance Distillation & Flow Matching):抛弃了传统的 DDPM 扩散模型,全面转向最优传输下的流匹配(Rectified Flow)。同时 dev 版本融入了指引蒸馏技术,无需负面提示词(CFG Batch Size 不需要翻倍),极大减少了计算开销并提升了生成轨迹的平滑度。
为了详细分析 FLUX.1-dev 的实现逻辑,我们以 Hugging Face diffusers 库的实现作为入口。下面是 FLUX.1-dev 生成图像的基础代码:
1 | |
核心组件分析
基于 diffusers 中的 FluxPipeline,FLUX 的生成管线依赖四个主要组件:
- Text Encoders: 精简而强大的双文本编码器。仅保留 CLIP-L(提取全局池化语义特征)和巨大的 T5-v1.1-XXL(提取长达 512 长度的底层细节序列特征)。
- VAE (AutoencoderKL): 16 通道高压缩比 VAE。保留了极度惊人的像素细节和极强的文字重建能力。
- Scheduler (
FlowMatchEulerDiscreteScheduler): 流匹配调度器。模型直接预测向量场(Vector Field),去噪轨迹更为平滑。 - Transformer Backbone (
FluxTransformer2DModel): 高达 120 亿参数的混合架构 DiT,由 19 层双流块和 38 层单流块串联组成。
数据输入到输出的完整尺度变化
FLUX 将多模态融合与空间坐标系做到了极致。以生成 1024 × 1024 图像、标准 dev 设定为例,我们来追踪数据流在 Transformer 前向传播中的尺度变化(FLUX dev 摒弃了传统的 CFG 机制,Batch Size 无需乘 2):
- Batch Size (N): 1 (无负向提示词)
- 隐通道数 ©: 16
- 隐图像尺寸 (H × W): 128 × 128 (1024 的 8 倍降采样)
- Patch Size (p): 2
- 隐藏层维度 (D): 3072
- 注意力头数 (H): 24 (单头维度 )
- 文本序列长度 (L_txt): 512
1. 文本编码与条件融合 (Pipeline 级别)
- 操作: 分别使用 T5 和 CLIP 提取文本特征。生成随机初始噪声,将当前 Timestep 与指引系数(Guidance Scale)结合,并融入 CLIP 的特征。
- Shape:
- T5 序列特征
prompt_embeds➔ 1 × 512 × 4096 - 隐特征图
hidden_states➔ 1 × 16 × 128 × 128 - 全局条件
temb(融合了 Time, Guidance, CLIP) ➔ 1 × 3072
- T5 序列特征
2. Patchify 与特征映射阶段
- 操作 1 (Image Patchify): 128 × 128 的隐特征图切分为 2 × 2 的 Patch,总数 。每个 Patch 展平后维度为 。经过
x_embedder升维至 3072 维。- Shape: 图像序列 ➔ 1 × 4096 × 3072
- 操作 2 (Text Mapping): T5 文本序列通过
context_embedder降维对齐 Transformer 维度。- Shape: 文本序列 ➔ 1 × 512 × 3072
3. RoPE 坐标体系的统一与频率预计算
这是 FLUX 打破模态隔阂的核心。在进入 Transformer Block 前,FLUX 为每个 Token 建立了一个三维统一坐标系 (c, y, x),计算出用于 Attention 层旋转 Query 和 Key 的复数频率矩阵:
- 图像 2D 坐标 (
image_ids): 按照 64 × 64 网格赋予(0, y, x)坐标。Shape ➔ 4096 × 3 - 文本 1D 坐标 (
text_ids): 视文本为只在 x 轴延伸的单行像素,赋予(0, 0, x)坐标。Shape ➔ 512 × 3 - 联合与频率生成: 两者拼接为 4608 × 3 的坐标系。为了将坐标映射到 128 维的 Attention Head 空间,FLUX 将维度劈开:前 64 维监听 y 轴生成频率,后 64 维监听 x 轴生成频率。
- Shape: 最终生成的复数旋转频率字典
freqs➔ 1 × 4608 × 128。
4. DoubleStream Blocks:双流协同计算 (1 - 19层)
在此阶段,图像和文本序列保持物理独立。
- 独立调制:
temb分别生成专属参数(AdaLN),独立调制图像和文本序列。 - 带 RoPE 的联合注意力: 图像与文本分别乘以投影矩阵生成 Q、K、V。此时,刚刚计算的
freqs矩阵发挥作用,Q 和 K 的每个 Head 在计算点积前,先与freqs进行逐 Token 的复数乘法旋转。随后两者在序列维度拼接(长度 4608)互相 Attention。完成后立刻拆分。 - Shape: 图像序列维持 1 × 4096 × 3072,文本序列维持 1 × 512 × 3072。各自经过专属 FFN。
5. SingleStream Blocks:单流深度融合 (20 - 57层)
完成初步对齐后,双模态的优待到此为止。
- 强制物理拼接: 代码底层执行
Concat操作,将图像和文本融为一体。- Shape: 合成联合序列 ➔ 1 × 4608 × 3072。
- 统一调制与计算: 联合序列被当作一个整体,接受统一的 AdaLN 调制。在经过统一的 Self-Attention(同样施加
freqs的 RoPE 旋转)和巨大的共享 FFN 时,模型强迫文本底层语义与图像像素排布发生深层物理纠缠。 - Shape: 输出维度维持 1 × 4608 × 3072。
6. 输出重建与 VAE 解码
- 操作 1 (文本舍弃): 离开最后一层后,直接切掉前 512 个文本 Token。
- Shape: 图像序列 ➔ 1 × 4096 × 3072
- 操作 2 (最终投影 & 反分块): 输入
proj_out将 3072 维还原到目标维度 。随后将 4096 长度的网格解包为二维排列。- Shape: 隐特征图 ➔ 1 × 16 × 128 × 128
- 操作 3 (VAE 解码): 送入 16 通道的 VAE 解码器 (
vae.decode)。- Shape: 最终输出 RGB 图像 ➔ 1 × 3 × 1024 × 1024
FLUX.1-dev架构分析
https://huan-yin.github.io/2026/04/14/FLUX-1-dev架构分析/